
Markov Zinciri Algoritması
Bu makale özgün bir makale olmayıp Kerninghan ve Pike'ın The Practice of Programming kitabındaki 3. bölümün tercüme edilmiş, kısaltılmış, değiştirilmiş halidir. Makaledeki tüm eksikliklerden, teknik yanlışlıklardan, vs. Emre "FZ" Sevinç sorumludur.
Anlamlı Gibi Görünen (!) Doğal Dil Üretimi
Bir insan dilindeki (İngilizce gibi) cümleleri belli bir algoritmaya göre üretmek ve bunların doğal görünmesini yani sanki bir insan tarafından üretilmiş gibi görünmelerini sağlamak mümkün müdür? Bunun için hangi algoritma kullanılabilir ve bu algoritma hangi "bilgisayar dillerinde, nasıl" uygulanabilir?
Gelişigüzel dil üretiminde en basitinden dili oluşturan alfabeden yola çıkabilir ve harfleri (ve boşlukları, noktalama işaretlerini, vs.) gelişigüzel (random) dizerek bir çıktı elde edebiliriz:
asdfazxc zxceaqwe weaczcsd asdfgg
Pek anlamlı görünmüyor! Bir adım öteye geçip söz konusu dildeki (bu makale bağlamında İngilizce) harf frekanslarını kullanabiliriz. Yani dilin insanlar tarafından doğal kullanımında en çok tekrarlanan harflerin daha yüksek olasılıkla görünmesini sağlayarak örneğin şöyle bir çıktı elde edebiliriz:
idtefoae tcs trder jcii ofdslnqetacp t ola
Ancak yukarıdaki harf dizisinin de anlamlı olduğu söylenemez. O halde bir adım daha ileri gidip İngiliz dilini oluşturan sözcükleri gelişigüzel dizen bir algoritma ile bir şeyler yapmayı deneyebiliriz:
zenith book on car cake take rule over silly sample
Eğer daha iyi ve doğal görünen sonuçlar istiyorsak o zaman yapmamız gereken şey daha çok "yapısal bilgi" barındıran bir istatistik modeldir, örneğin harf frekanslarının ötesinde kendi içinde anlamlı söz öbeklerinin frekansı gibi. Peki bu tür bir istatistiksel bilgiyi nasıl elde edebiliriz?
Bunun için söz gelimi upuzun bir İngilizce metin alıp bunu detaylı olarak inceleyebiliriz ancak bundan daha basit ve eğlenceli bir yöntem mevcuttur. Herhangi bir metni alıp, dilin o metindeki kullanımının istatistiksel yapısını yansıtan bir modele göre yepyeni ve gelişigüzel kurulmuş bir metin üretebiliriz.
Markov Zinciri
Yukarıdakine benzer bir düşüncenin somut uygulamalarından birinin ismi Markov Zinciri Algoritmasıdır. Eğer girdi metnini üst üste binmiş (overlapping) söz öbekleri (phrases) olarak görürsek, bu algoritma her söz öbeğini iki parçaya ayırır: birçok sözcükten oluşan bir "prefix" grubu ve tek sözcükten oluşan, "prefix"i takip eden bir "suffix". Markov Zinciri Algoritması, prefix grubunu takip eden bir suffix'i gelişigüzel seçer ancak bunu yaparken orjinal metindeki sözcük grubunun istatistiksel yapısını yansıtır. Genellikle üç sözcükten oluşan söz öbekleri - iki sözcüklük prefix grubu ve tek sözcüklük suffix - ilginç sonuçlar üretebilir. Algoritmayı daha açık ifade etmek gerekirse şöyle yazabiliriz:
w1 ve w2 değişkenleri girdi metnindeki ilk iki sözcüğün değerini alsın
w1 ve w2yi bas
döngü:
w1 w2 prefix grubunu takip eden suffix'lerden birini
gelişigüzel seç ve bunu w3 değişkenine yerleştir
w3ü bas
w1e w2yi, w2ye w3ü yerleştir
döngüye devam et
Algoritmanın nasıl çalıştığını somut bir İngilizce metin üzerinde inceleyelim:
Show your flowcharts and conceal your tables and I will be mystified. Show your tables and your flowcharts will be obvious. BİTİŞ
Bu örnek girdi metnindeki bazı sözcük çiftlerini ve bunları takip eden sözcükleri yazmak gerekirse:
| Girdi prefix'i: | Takip eden suffix'ler: |
| Show your | flowcharts tables |
| your flowcharts | and will |
| flowcharts and | conceal |
| flowcharts will | be |
| your tables | and and |
| will be | mystified. obvious. |
| be mystifed. | Show |
| be obvious. | BİTİŞ |
Markov Zinciri Algoritması yukarıdaki girdi metnini işlemeye başlar ve önce Show your sözcük öbeğini basar hemen ardından ise ya flowcharts ya da tables sözcüğünü seçer. Eğer birincisini seçerse o zaman halihazırdaki prefix your flowcharts olur ve bunu takip eden suffix de and ya da will olacaktır. Eğer ikincisini yani tables sözcüğünü seçerse o bir sonraki sözcük and olmak durumundadır. Bu işlemler dizisi "yeterince" sözcük üretilene ya da suffix olarak BİTİŞ ile karşılaşana dek devam eder.
Programımız bir İngilizce metni okuyacak ve sabit sayıda sözcükten oluşan söz öbeklerinin (prefix'ler) metin içinde kaç göründükleri bilgisine yani frekanslarına dayanarak ve Markov Zinciri Algoritmasını kullanarak yeni bir metin oluşturacaktır. Bir prefix'i oluşturan sözcüklerin sayısı algoritmanın parametrelerinden biridir ve bizim örneğimizde bu sayı 2'dir. Prefix'teki sözcük sayısını düşürmek anlamlı metin üretmeyi güçleştirecek, artırmak ise girdi metninin olduğu gibi kopyalanmasına yol açacak ve bu da ilginç bir sonuç oluşturmasını engelleyecektir. Deneysel olarak görülmüştür ki İngilizce metinler için iki sözcükten oluşan bir prefix kullanmak ve buna göre bir suffix seçmek uygun olmakta, orjinal metne benzeyen, anlamlı gibi görünen ama aslında o kadar da anlamlı olmayan bir metnin üretilmesine yol açmaktadır.
Bir "sözcük" nedir? Açıktır ki bir dizi karakterden oluşan bir öbektir ancak sözcüğe bitişik olan noktalama işaretleri de onun bir parçası olarak kabul edilmeli midir? Yani "word" ve "word," iki farklı sözcük olarak mı işlenecektir? Bu şekilde kabul edilmesi çıktı metinde noktalama işaretlerinin de dağıtılmasını sağlamakta ve sonuçları daha ilginç kılmaktadır, böylece çıktı metnin grameri de dolaylı yoldan etkilenmiş olmaktadır. Dezavantajı ise açılıp da kapanmayan parantezler, tırnaklar gibi hatalı durumlardır. Bu sebeplerden ötürü "sözcük" iki boşluk arasında kalan herhangi bir karakter öbeği olarak tanımlanacaktır. Böylece girdi dili üzerinde herhangi bir kısıtlama getirmemiş ve noktalama işaretlerini de elemek ya da özel olarak işlemek gibi bir görevden kurtulmuş oluruz. Pek çok programlama dilinde girdinin "boşluklarla ayrılmış sözcükler" olarak yorumlanmasını sağlayan rutinler bulunduğu için yukarıdaki tanımlama algoritmanın somut olarak uygulanmasında da bize kolaylık sağlayacaktır.
Bu yöntem yüzünden çıktıdaki tüm sözcükler, tüm iki sözcüklü öbekler ve tüm üç sözcüklü öbekler girdi metninde de bulunmak zorundadır ancak sonuç olarak orataya dört ya da daha çok sözcükten oluşan söz öbekleri de çıkacaktır. Bu algoritmayı çalıştıran bir programa Richard Stallman'ın Özgür Yazılım hareketi ile ilgili bir kitabın ilk bölümü verdildiğinde şöyle bir çıktı elde edilmiştir (bir kısmı gösterilmiştir):
"The new printer was a refusal on the laser printer," Stallman says. Memory is a sizable one. It wasn't long before Stallman, increasingly an outcast even within the electrical plumbing of the Golden Rule, the baseline moral dictate to do unto others as you would have been no righteous anger, an emotion that, as we soon shall see, has propelled Stallman's career as surely as any political ideology or ethical belief. "From that day forward, I decided this was something I could express them in a more ordinary path, one balancing the riches of a human operator. Figuring that these human operators would always be on hand to fix the problem, chances were higher that the problem and the AI Lab and its indigenous population of programmers. Indeed, the best programmers at the time, a reflection of both the commercial value of the compromise deal that allowed hackers to work on the laser printer," Stallman says. Memory is a funny thing.
Algoritmanın Bilgisayar Programı Olarak Uygulanması
Girdi metninin büyüklüğü ne kadar olacaktır? Program ne kadar hızlı çalışmalıdır? Bu programdan bir kitap uzunluğunda veri işlemesini isteyeceğiz dolayısı ile n = 100.000 sözcüğü işleyebilecek kapasitede olmasını beklemek doğaldır. Çıktı metni ise yüzlerce, belki de binlerce sözcükten oluşacaktır ve bu veri program tarafından birkaç dakikada değil en fazla birkaç saniyede işlenmelidir.
Markov algoritması çıktı üretmeye başlamadan önce tüm girdiyi okumuş olmalıdır ve bunu bir şekilde hafızada depolamalıdır. Seçeneklerden bir tanesi tüm girdiyi tek bir uzun karakter dizisi şeklinde depolamaktır ancak yukarıda da belirtildiği gibi metni sözcüklere bölmek daha anlamlıdır. Eğer bu yapıyı tek tek her bir sözcüğü gösteren işaretçi (pointer) dizisi olarak kurarsak çıktı üretmenin kuralı basit olacaktır: Üretilecek her sözcük için girdi metnini tara, mevcut prefix'i takip eden suffix'lerden birini bul, bulduklarından bir tanesini gelişigüzel seçip bas ve işleme devam et. Ancak burada bir problem var: her bir sözcük üretimi için 100.000 sözcüklük diziyi taramamız gerekir ve misal 1000 sözcüklük bir çıktı üretmek istersek bu, yüz milyonlarca kıyaslama yapacağımız anlamına gelir. Dizi kıyaslaması vakit alan bir iştir özellikle yüz milyonlarca kez yapılması gerektiğinde.
İhtiyacımız olan şey bir prefix'i ve onun takip eden yani onunla bağlantılı (associated) suffix'leri depolayacak bir veri yapısıdır. Program iki aşamalı olarak çalışacaktır, birinci aşamada yukarıdaki yapı kurulacak; ikinci aşamada bu veri yapısı kullanılarak belli ölçüde gelişigüzel çıktı üretilecektir. Her iki aşamada da bir prefix'i çok hızlı bir şekilde bulabilmemiz gerekir: birinci aşamada, suffix'leri güncelleyebilmek için; ikinci aşamada ise olası suffix'lerden birini gelişigüzel seçebilmek için. Tüm bu ihtiyaçlarımızı karşılayacak olan veri yapısı bir "hash" tablosudur. Tablo anahtarları prefix'ler, tablo değerleri ise bunlara karşılık gelen suffix'ler olacaktır.
Örnek uygulamada iki sözcükten oluşan prefix'ler kullanılacaktır yani çıktıdaki her sözcük kendisinden önce gelen ikili sözcük grubu tarafından belirlenecektir. Prefix'i oluşturan sözcük sayısı program tasarımını etkilememelidir ve zaten program da en genel halde herhangi sayıda sözcükten oluşan prefix'leri kabul edebilmelidir ancak bu sayıyı sabitlemek programın tasarlanmasını ve anlaşılmasını kolaylaştırmaktadır. Prefix ve onu takip eden suffix'ler kümesi, Markov algoritmaları ile ilgili literatürde dendiği gibi bir durum (state) oluşturur ve bu tür algoritmaların temeli de bir durumdan diğer duruma geçişe dayanır.
Bir prefix verildiğinde onu takip eden tüm suffix'leri depolamamız gerekir ki daha sonra bunlara erişebilelim. Suffix'ler sıralı değildir ve birer birer eklenirler. Önceden kaç tane olacağını bilemeyiz bu yüzden de kolayca büyüyebilen bir liste ya da dinamik bir dizi gereklidir. Çıktı üretmeye başladığımızda belli bir prefix'le ilişkili, bağlantılı (associated) suffix'lerden bir tanesini gelişigüzel seçmemiz gerekir. Listedeki elemanlardan hiçbiri programın çalışması esnasında silinmeyecektir. Yani sadece ekleme söz konusudur. Bu şartları göz önünde bulundurduğumuzda her bir elemanı bağlı listelerden oluşan ve statetab olarak isimlendireceğimiz bir hash tablosu işimizi görecektir. Bu yapıyı şematik olarak şu şekilde düşünebiliriz:
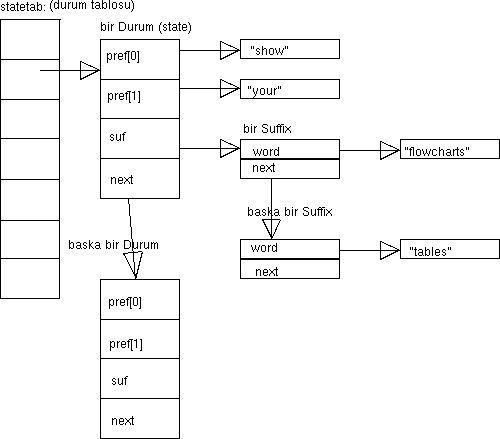
Markov Zinciri Algoritmasının C programlama dili ile uygulaması yukarıdaki yapı temel alınarak hazırlanmıştır. Bu uygulamada tüm yapı sıfırdan kurulmuş ve ekleme, arama, tarama gibi tüm işlemler açık ve detaylı olarak kodlanmıştır. C dilindeki uygulama en uzun olanıdır, bununla birlikte çalışabilir makina kodu olarak derlenebilmekte, bu hali ile en az yer kaplamakta ve en hızlı çalışan uygulama olmaktadır. C++ uygulaması ise STL (Standart Template Library) içindeki hazır ve genelleştirilmiş veri yapılarını ve algoritmaları kullanmaktadır, bu sayede hata yapma ihtimali çok daha düşük olmakta, bir önceki uygulamaya göre kodlaması çok daha bir soyut seviyede gerçekleşmekte ve kısa sürmektedir. Bu program da makina diline derlenebilmekle birlikte bir önceki örneğe kıyasla çok daha fazla yer kaplamakta ve daha yavaş çalışmaktadır. Algoritmanın AWK uygulaması mawk isimli AWK yorumlayıcısı tarafından çalıştırılmakta ve makina koduna derlenmemektedir. Söz konusu örnek ilk iki örneğe kıyasla çok daha kısa bir uygulama olup altyapı detaylarını programcıdan gizlemekte, onun algoritmaya yoğunlaşmasını sağlamaktadır. Son örnek uygulama ise Perl uygulaması olup yine bir yorumlayıcı (Perl) tarafından çalıştırılmaktadır. En az sayıda kod satırına sahip (18 kod satırı) bu örnek karakter dizisi işlemleri için özel olarak optimize edilmiş Perl tarafından çalıştırılmakta ve performans olarak C++ ve AWK uygulamalarını geçmekte, kodlama kolaylığı ve soyutluğu olarak ise birinci sırada yer almaktadır.
Kabaca örneklerin performanslarını değerlendirmek için aşağıdaki tabloya bakabiliriz (C uygulaması gcc 2.95.4 ile, C++ uygulaması g++ 2.95.4 ile derlenmiştir. AWK yorumlayıcısı olarak mawk kullanılmıştır. Sistem Debian GNU/Linux 3.0 (stable) çalıştıran 256 MB ana hafızalı ve 1000 Mhz'lik Intel Celeron işlemcisili bir bilgisayardır. Derleyici kullanılması durumunda herhangi bir optimizasyon parametresi devreye sokulmamıştır. Orjinal makalede kullanılan ve İncil'in bir bölümü olan bu örnek girdi dosyası olarak kullanılmıştır.) :
| Süre | Satır | Büyüklük | |
|---|---|---|---|
| C | 0.19 s | 145 | 7689 byte |
| C++ | 1.97 s | 55 | 155279 byte |
| AWK | 0.49 s | 20 | N/A |
| Perl | 0.45 s | 18 | N/A |
Sonsöz
Markov Zinciri Algoritması pek çok farklı İngilizce metine uygulanabilir ve anlamlı gibi görünen ama zorunlu olarak herhangi bir anlam içermeyen metinlerin üretilmesini sağlayabilir. Yapılan bazı denemelerde, deneklerin birtakım örnek çıktıları uzunca bir süre "anlamlı bir metinmiş" gibi ele aldıkları ve şüphelenmedikleri gözlemlenmiştir.
Bu algoritmanın sözcükler yerine farklı şeylere de uygulanması düşünülebilir: müzik notaları, bilgisayar programları, kullanıcı tepkileri (fare kliklemeleri, vs.). Doğal süreçlerin bu şekilde "yapaylaştırılması" ilginç sonuçlar doğurabilir.
Son olarak da, programlama tekniği açısında Perl ve AWK gibi diller kodlama kolaylığı ve pratiklik getirmekle birlikte C++ gibi nesneye yönelik diller farklı nesnelere aynı algoritmanın uygulanmasını kolaylaştırmakta, C dili ise belli bir ölçüde esneklik sunmakta ve asıl avantakını hafıza ve hız performansında göstermektedir.










iyi eglenceler..
ingilizce postmodern yazilar:
http://www.elsewhere.org/cgi-bin/postmodern/
fransizca postmoderne yazilar:
http://cristal.inria.fr/cgi-bin/postmoderne
http://cristal.inria.fr/cgi-bin/dada?brag.pb
// A SubGenius brag generator (Andrew C. Bulhak)
http://cristal.inria.fr/cgi-bin/dada?crackpot.pb
// A crackpot rant generator (Andrew C. Bulhak)
http://cristal.inria.fr/cgi-bin/dada?eqn.pb
// A generator of bogus equations in LaTeX format (Andrew C. Bulhak)
http://cristal.inria.fr/cgi-bin/dada?exam.pb
// A script to generate intimidating-looking but bogus
// examination questions. (Andrew C. Bulhak - unfinished)
// Expanded version by Lars Gustavsson 2000-08-03
http://cristal.inria.fr/cgi-bin/dada?exam_se.pb
// A script to generate intimidating-looking but bogus
// examination questions. (Andrew C. Bulhak - unfinished)
// Expanded version by Lars Gustavsson 2000-08-03
// Translated to Swedish 2000-08-03
// by Lars Gustavsson
http://cristal.inria.fr/cgi-bin/dada?legal.pb
// A script to generate legalese (Andrew C. Bulhak)
http://cristal.inria.fr/cgi-bin/dada?manifesto.pb
// A manifesto generator (Andrew C. Bulhak)
http://cristal.inria.fr/cgi-bin/dada?manifesto.pb
// The Postmodernism Generator (Andrew C. Bulhak)
http://cristal.inria.fr/cgi-bin/dada?pomo_fr.pb
// The Postmodernism Generator (Andrew C. Bulhak)
// Translated in French by Daniel de Rauglaudre
http://cristal.inria.fr/cgi-bin/dada?silly-word.pb
// A silly word generator
http://cristal.inria.fr/cgi-bin/dada?spout.pb
// The SubGenius Profunditied Generation Matrix
ZoM