
Yüksek performanslı Linux kümeleme, 1. Bölüm: Kümelemenin ilkeleri
Linux küme teknolojisiyle Yüksek Performanslı Bilgiişleme ilişkin temel kavramlara giriş
Düzey: Başlangıç
Aditya Narayan
(aditya_pda@hotmail.com), QCD Microsystems Kurucusu
27 Eylül 2005
Yüksek Performanslı Bilgiişlemin (HPC) kolaylaşmasının nedenlerinden biri açık kaynak yazılım kavramlarının kullanılmaya başlanması, bir başka nedeni ise kümeleme teknolojisinin iyileştirilmesidir. Sunulan iki makaleden ilkinde, kullanılan kümelerin türleri, bu kümelerin kullanım alanları, kümelemenin yüksek performanslı bilgiişlem için önem kazanmasının nedenleri ve yüksek performanslı bilgiişlemde Linux'un® rolü gibi konular tartışılmaktadır.
Linux kümelemesi bugünlerde birçok sektörde yaygınlaşıyor. Kümeleme teknolojisinin ilerlemesi ve açık kaynak yazılımlarının daha çok kabul görmesiyle, şimdi süper bilgisayarları geleneksel yüksek performanslı makinelerin maliyetinin çok az bir kısmıyla yaratmak mümkün.
Bu iki bölümlü makalede, Linux kümeleme teknolojisiyle Yüksek Performanslı Bilgiişlem gerçekleştirilmesine ilişkin kavramlar tanıtılmakta ve küme oluşturma ve paralel programlar yazma işlemlerini nasıl yapacağınız gösterilmektedir. Bu bölümde, farklı küme türleri, kümelerin kullanım alanları, Yüksek Performanslı Bilgiişlemin bazı ilkeleri ve kümeleme teknolojisinin yaygınlaşma nedenleri anlatılmaktadır. 2. Bölümde paralel algoritmalar, paralel program yazma ve küme oluşturma işlemlerinin nasıl yapıldığı ve karşılaştırmalı küme değerlendirme konuları ele alınmaktadır.
Birçok HPC sistemi paralellik kavramını kullanır. Yazılım platformlarının birçoğu HPC odaklıdır, ancak önce konunun donanımla ilgili yönlerine bakalım.
HPC donanımları üç kategoriye ayrılır:
- Simetrik çoklu işlemciler (SMP)
- Vektör işlemcileri
- Kümeler
Simetrik çoklu işlemciler (SMP)
SMP, birden çok işlemcinin aynı belleği paylaştığı bir HPC mimarisi türüdür. (Kümelerde, yoğun olarak paralel işlemciler (MPP'ler) olarak da bilinen bu işlemciler, aynı belleği paylaşmaz; bu konuyu daha ayrıntılı olarak ele alacağız). SMP'ler genellikle MPP'lerden daha pahalıdırlar ve ölçeklenme düzeyleri daha düşüktür.
Vektör işlemcilerinde, adından da anlaşılacağı gibi, CPU, diziler ya da vektörlerle iyi performans sağlayacak şekilde optimize edilmiştir. Vektör işlemci sistemler, yüksek performans sunar ve 1980'lerde ve 1990'ların başında en yaygın HPC mimarisi olarak kullanılmıştır ancak son yıllarda kümeler çok daha fazla yaygınlaşmıştır.
Kümeler son günlerde en yaygın olan HPC donanımı türüdür; bir küme, bir dizi MPP'den oluşur. Bir kümedeki bir işlemci genellikle düğüm olarak adlandırılır ve kendi CPU, bellek, işletim sistemi ve G/ç altsistemine sahiptir ve diğer düğümlerle iletişim kurabilir. Günümüzde, Linux ve diğer açık kaynak yazılımlarını çalıştıran iş istasyonlarının kümedeki bir düğüm olarak kullanılması yaygındır.
Bu HPC türlerinin farklarını göreceksiniz ancak önce kümelemeyi ele alalım.
"Küme" terimi farklı bağlamlarda farklı anlamlara gelebilir. Bu makalede üç küme türü ele alınmaktadır:
- Yedeğe geçmeli kümeler
- Yük dengelemeli kümeler
- Yüksek performanslı kümeler
En basit yedeğe geçmeli kümede iki düğüm bulunur. Düğümlerden biri etkindir, diğeri beklemededir ancak sürekli olarak etkin olanı izler. Etkin düğüm çalışmazsa, beklemedeki düğüm devreye girerek önemli bir sistemin çalışmaya devam etmesini sağlar.
Yük dengelemeli kümeler Web siteleri tarafından sıkça kullanılır. Bu Web sitelerinde birkaç düğüm aynı siteye hizmet eder ve her yeni Web sitesi isteği dinamik olarak daha düşük yüklü bir düğüme yöneltilir.
Bu kümeler, zaman ağırlıklı hesaplamalar için paralel programlar çalıştırmak üzere kullanılır ve bilim dünyasının özel ilgi alanıdır. Bu kümeler genellikle simülasyonları ve standart donanımlar üzerinde çalışması aşırı zaman alacak diğer CPU ağırlıklı programları çalıştırır.
Şekil 1'de basit bir küme gösterilmiştir. Bu yazı dizisinin 2. Bölümünde, böyle bir kümenin nasıl yaratılacağı ve buna ilişkin programların nasıl yazılacağı gösterilmektedir.
Şekil 1. Basit küme
"Grid" bilgiişlem, genellikle, gevşek bağlı sistemler arasında işbirliği yapılan hizmet odaklı mimariye (SOA) ilişkin geniş anlamlı bir terimdir. Küme tabanlı HPC, düğümlerin sıkı bağlı olduğu özel bir grid bilgiişlem türüdür. En çok bilinen başarılı grid bilgiişlem projelerinden biri Search for Extraterrestrial Intelligence programı olan SETI@home'dur. Bu programda, bir milyon ev PC'sinin boştaki CPU döngüleri, ekran koruyucular aracılığıyla radyo teleskop verilerini çözümlemek için kullanılmıştır. Bir başka başarılı proje de, protein katlanması hesaplamalarına ilişkin Folding@Home projesidir.
Yüksek performanslı kümelerin en sık kullanıldığı alanlar
Hemen hemen tüm sektörlerde hızlı işlem gücüne gereksinim duyulur. Bilgisayarların ucuzlaması ve hızlanmasıyla birlikte, teknolojik avantajlardan yararlanmak isteyen şirketler artmaktadır. Bilgisayar işlem gücü gereksinimlerinin üst sınırı yoktur; hızlı güç artışıyla birlikte bile, talep sunulandan çok fazladır.
Protein molekülleri, sonsuz sayıda 3B şekle girebilecek uzun ve esnek zincirlerdir. Doğada, bir çözeltiye koyulduklarında, hızlı bir şekilde doğal durumlarına "katlanırlar". Yanlış katlanmanın Alzheimer gibi çeşitli hastalıklara yol açtığına inanılmaktadır; bu nedenle, protein katlanması çalışmaları büyük önem taşımaktadır.
Bilim adamlarının protein katlanmasını anlamak için kullandıkları yöntemlerinden biri bilgisayarlarda gerçekleştirilen protein katlanması simülasyonlarıdır. Doğada, katlanma hızlı gerçekleşir (yaklaşık olarak saniyenin milyonda biri kadar kısa sürede), ancak bunun simülasyonu sıradan bir bilgisayarda onlarca yıl sürebilecek kadar karmaşıktır. Bu çalışma alanı benzer birçok alanın bulunduğu bir sektör için küçük olsa da ciddi bir hesaplama gücüne gerek vardır.
Bu sektördeki diğer çalışma alanları arasında farmakolojik modelleme, sanal cerrahi eğitim, koşul ve tanılama görselleştirmeleri, toplam kayıtlı tıbbi veritabanları ve İnsan Geni Projesi yer alır.
Sismogramlar yeryüzünün ve denizaltının iç yapısı hakkında ayrıntılı bilgi sağlar ve bu verilerin çözümlenmesi, petrol ve diğer kaynakların saptanmasına yardımcı olur. Küçük alanların bile yeniden yapılandırılması için terabaytlarca veri gereklidir; hiç şüphesiz bu çözümleme için çok fazla hesaplama gücüne gerek vardır. Bu alandaki hesaplama gücü talebinin fazlalığı nedeniyle genellikle bu çalışmalar için süper bilgiişlem kaynakları kiralanmaktadır.
Deprem tahminlerine yönelik sistem tasarımları ve güvenlik çalışmaları için çok spektrumlu uydu görüntüleme sistemi tasarımları gibi benzer bilgiişlem gücü gerektiren başka jeolojik çalışmalar da vardır.
Mühendislikte, uçak motoru tasarımı gibi yüksek çözünürlüklü etkileşimli grafiklerin kullanılması, söz konusu verilerin çokluğu nedeniyle her zaman performans ve ölçeklenebilirlik açısından güç olmuştur. Küme tabanlı teknikler, ekran görüntüsünü boyama işleminin, ekrandaki kendi bölümlerinin gerçeklemesini yapmak için kendi grafik donanımını kullanan ve piksel bilgilerini, ekranın birleştirilmiş görüntüsünü derleyen bir ana düğüme ileten çeşitli küme düğümleri arasında bölündüğü bu alanda yararlı olmuştur.
Bu sektör örnekleri yalnızca buzdağının görünen yüzüdür; astrofiziksel simülasyon, hava durumu simülasyonu, mühendislik tasarımı, finansal modelleme, portföy simülasyonu ve filmlerdeki özel efektler gibi daha birçok uygulama için çok çeşitli hesaplama kaynaklarına gereksinim vardır. Bu güce olan talep giderek artacaktır.
Linux ve kümeler HPC'yi nasıl değiştirdi?
Küme tabanlı bilgiişlemin öncesinde, tipik bir süper bilgisayar, üzerindeki özel donanım ve yazılımlar nedeniyle genellikle bir milyon dolardan fazlasına mal olan bir vektör işlemcisiydi.
Linux ve kümelemeye yönelik ücretsiz sunulan diğer açık kaynak yazılım bileşenleri ve piyasadaki donanımlardaki geliştirmelerle birlikte, durum şu anda oldukça farklı. çok küçük bir bütçeyle güçlü kümeler oluşturabilir ve gerektiğinde ek düğümler ekleyebilirsiniz.
GNU/Linux işletim sistemi (Linux), kümelerin kullanımını büyük oranda teşvik etmiştir. Linux birçok çeşitli donanım üzerinde çalışır ve yüksek kaliteli derleyiciler ve paralel dosya sistemleri ve MPI dağıtımları gibi diğer yazılımlar ücretsiz olarak sağlanıp Linux üzerinde kullanılabilir. Ayrıca, Linux ile, kullanıcılar çekirdeği kendi iş yükleri için özelleştirebilirler. Linux, HPC kümeleri oluşturmak için kabul gören ve sık kullanılan bir platformdur.
Donanımın anlaşılması: Vektör ve küme karşılaştırması
HPC donanımı anlamak için vektör bilgiişlem örneğini küme örneğiyle karşılaştırmak yararlı olabilir. Her ikisi de bilgiişlem teknolojileridir (bir vektör süper bilgisayarı olan Earth Simulator hala en hızlı 10 süper bilgisayardan biridir).
Temelde, hem vektör hem de sayıl işlemciler yönergeleri bir saate göre yürütür; bunların birbirinden ayrıldığı nokta, vektör işlemcilerinin, Yüksek Performanslı Bilgiişlemde sık kullanılan vektör içeren hesaplamaları (matris çarpımı gibi) paralel hale getirebilmesidir. Bunu örneklemek gerekirse, iki a ve b çift dizisi olduğunu ve x[i]=a[i]+b[i] olacak şekilde üçüncü bir x dizisi yaratmak istediğinizi varsayalım.
Toplama ya da çarpma gibi kayan noktalı tüm işlemler birkaç ayrı adımda gerçekleştirilir:
- Üstler ayarlanır
- Önemli basamaklar toplanır
- Sonuçta yuvarlama hatası vb. olup olmadığına bakılır
Bir vektör işlemcisi bu iç adımları bir boruhattında işleme (pipelining) tekniği kullanarak paralel hale getirir. Şekil 2'de gösterildiği gibi bir kayan noktalı toplama işleminde altı adım olduğunu varsayalım (IEEE aritmetik donanımındaki gibi).
Şekil 2. IEEE aritmetik donanımıyla altı adımlı bir boruhattı
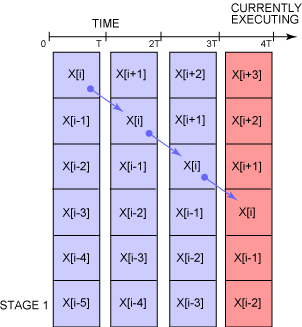
Bir vektör işlemcisi bu altı adımı paralel olarak gerçekleştirir -- eklenmekte olan sıra i'deki dizi öğeleri 4. aşamalarındaysa, vektör işlemcisi sıra (i+1)'deki öğe için 3. aşamayı, sıra (i+2)'deki öğe için 2. aşamayı yürütür ve bu şekilde devam eder. Gördüğünüz gibi, altı adımlı bir kayan noktalı toplama işleminde, tüm aşamalar herhangi bir zamanda etkin olduğundan (Şekil 2'de kırmızı renkle gösterilmiştir) hızlandırma faktörü altı kereye çok yakın olur (başlangıçta ve sonda, altı adımın tümü etkin değildir). Bunun sağladığı en büyük avantajlardan biri paralel duruma getirme işleminin, arka planda gerçekleşmesi ve bunu programlarınızda açıkça kodlamanıza gerek olmamasıdır.
çoğunlukla, altı adımın hepsi paralel olarak yürütülerek neredeyse performansı altı kat artırır. Oklar sıra i'de bulunan dizi dizinindeki işlemleri gösterir.
Vektör işlemleriyle karşılaştırıldığında, küme tabanlı bilgiişlem özünde çok farklı bir yaklaşıma sahiptir. Küme tabanlı bilgişlemde, özel olarak optimize edilmiş vektör donanımı yerine, standart sayıl işlemciler kullanılır; ancak bu sayıl işlemciler birkaç hesaplamanın paralel olarak yapılması için çok sayıda kullanılır.
Kümelerin bazı özellikleri şunlardır:
- Kümeler, ticari donanım kullanılarak oluşturulur ve vektör işlemcilere göre çok daha ucuzdur. Birçok durumda, fiyatları bir büyüklük sırasından daha düşüktür.
- Kümelerde, iletişim için bir ileti geçişi paradigması kullanılır ve dağınık donanımlardan yararlanmak için programların açık bir şekilde kodlanması gerekir.
- Kümeleri kullanarak kümeye gerektiği kadar düğüm ekleyebilirsiniz.
- Açık kaynak yazılım bileşenleri ve Linux, yazılım maliyetlerini düşürmektedir.
- Daha az yer kaplayan, daha az güç kullanan ve daha az soğutma gerektiren kümelerin bakım masrafları ise çok daha düşüktür.
Paralel programlama ve Amdahl Kanunu
Küme üzerinde yüksek performans elde edilmesi konusunda yazılım ve donanım birlikte çalışır. Temeldeki donanımdan açıkça yararlanmak için program yazılması ve bir küme üzerinde iyi performans sağlamaları için varolan paralel olmayan programların yeniden yazılması gerekir.
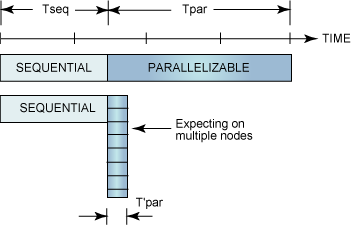
Bir paralel program aynı anda birçok işlem gerçekleştirir. Bu işlemlerin sayısı karşılaşılan soruna göre değişir. Bir programın harcadığı toplam sürenin 1/N kadarının paralel duruma getirilemeyecek bir bölümde yer aldığını, geri kalan (1-1/N) kadar sürenin de paralel duruma getirilebilecek bir bölümde olduğunu varsayalım (bkz. Şekil 3).
Şekil 3. Amdahl Kanunun Gösterimi
Teorik olarak, paralel bölümü sıfır sürede yapmak için sonsuz sayıda donanım uygulayabilirsiniz, ancak ardışık bölümde bir gelişme olmaz. Sonuç olarak, elde edebileceğiniz en iyi hız, programı özgün sürenin 1/N kadarında yürütmektir. Paralel programlamada, bu durum Amdahl Kanunu olarak bilinir.
Amdahl Kanunu, bir sorun üzerinde yalnızca tek bir dizisel işlemci kullanımına karşılık paralel işlemci kullanımıyla sağlanan hızlanmayı yönetir. Hızlanma (speedup) bir programın dizisel olarak (bir işlemciyle) işlem yapmak için harcadığı sürenin paralel olarak (birçok işlemciyle) işlem yapmak için harcadığı süreye bölünmesi olarak tanımlanır.
|
Bu formülde, T(j), j sayıda işlemci kullanıldığında programın yürütüldüğü süredir.
Şekil 3'te, paralel işlemler için yeterli sayıda düğüm kullanılarak T'par sıfıra yaklaştırılabilir ancak Tseq değişmez. En iyi durumda, paralel olan örnek, özgün örnekten 1+Tpar/Tseq değerinden daha hızlı olamaz.
Paralel program yazmanın en güç yanı N değerini mümkün olduğunca büyük yapmaktır. Ancak burada ilginç bir durum var. Normalde, daha büyük sorunları daha güçlü bilgisayarlarda ele alırsınız ve (siz programı değiştirmeyi ve paralel duruma getirilebilir kısmını, kullanılabilir kaynakları optimize etmek için artırmayı denediğiniz için) genellikle kodun ardışık bölümleri üzerinde harcanan sürenin oranı, sorunun boyutu arttıkça azalır. Bu nedenle, N değeri otomatik olarak artar. (Bu makalede Kaynaklar başlıklı sonraki bölümde yer alan Amdhal Kanununa bakın.)
Paralel programlama yaklaşımları
Paralel programlamayla ilgili iki yaklaşıma göz atalım: dağınık bellek yaklaşımı ve paylaşılan bellek yaklaşımı.
Bu yaklaşım için bir ana-bağımlı düğüm modelini kullanmak yararlı olabilir.
- Ana düğüm işi birkaç bağımlı düğüm arasında bölüştürür.
- Bağımlı düğümler kendi görevlerinde çalışır.
- Bağımlı düğümler gerektiğinde kendi aralarında iletişim kurar.
- Bağımlı düğümler ana düğüme geri döner.
- Ana düğüm sonuçları toplar, işi daha da dağıtır ve bu şekilde devam eder.
Bu yaklaşımdaki kaçınılmaz sorunlar, dağınık bellek düzeninden kaynaklanır. Her düğüm yalnızca kendi belleğine erişebildiğinden, veri yapılarına erişmek isteyen başka bir düğüm olduğunda, bu veri yapılarının çoğaltılması ve ağ üzerinden gönderilmesi gerekir. Bu durum ağdaki işyükünü artırır. Dağınık bellekli verimli programlar yazarken bu dezavantajları ve ana-bağımlı düğüm modelini aklınızda bulundurun.
Paylaşılan bellek yaklaşımında, bellek tüm işlemcilerde ortaktır (SMP gibi). Bu yaklaşımda, dağınık bellek yaklaşımında sözü edilen sorunlarla karşılaşılmaz. Ayrıca, tüm veriler tüm işlemciler tarafından kullanılabildiğinden ve ardışık programlamadan çok farklı olmadığından bu tür sistemler için programlama yapmak daha kolaydır. Bu sistemlerde, karşılaşılan temel güçlük ölçeklenebilirliktir; fazladan işlemci eklemek kolay değildir.
Paralel programlama (tüm programlama türleri gibi), her zaman önemli tasarım ve performans geliştirmelerine yer verdiğinden bilim olduğu kadar bir sanattır. Paralel programlamanın bilgiişlemde özel bir yeri vardır; bu yazı dizisinin 2.Bölümünde paralel programlama platformları ve örnekleri incelenmiştir.
G/ç dosyası ne zaman bir darboğaz haline gelir?
Bazı uygulamaların sık sık büyük miktarlarda veri okuması ve bunları diske yazması gerekir ve bu işlem bir hesaplamanın en yavaş adımıdır. Bunun için hızlı sabit sürücüler kullanmak yararlı olur ancak bunların da yeterli olmadığı zamanlar vardır.
Bu sorun, özellikle, bir fiziksel disk bölümü tüm düğümler arasında paylaştırıldığında (örneğin, NFS kullanılarak) ortaya çıkar ve buna Linux kümelerinde sık rastlanır. İşte paralel dosya sistemleri de bu durumlarda yarar sağlar.
Paralel dosya sistemleri bir dosyadaki verileri G/ç düğümleri olarak adlandırılan, kümedeki birden çok düğüme bağlı birkaç disk üzerine dağıtır. Bir program bir dosyayı okumayı denediğinde, bu dosyanın küçük bölümleri birkaç diskten paralel olarak okunur. Bu, herhangi bir disk denetleyicisi üzerindeki yükü azaltır ve disk denetleyicisinin daha çok isteği işlemesini sağlar. (PVFS, açık kaynak paralel dosya sistemi için iyi bir örnektir; standart IDE sabit diskleri kullanan Linux kümelerinde 1Gb/sn'den daha iyi disk performansı sağlanmıştır.)
PVFS, bir Linux çekirdek modülü olarak sunulur ve Linux çekirdeğinin içine de yerleştirilebilir. Konunun temelindeki kavram basittir (bkz. Şekil 4):
- Bir meta veri sunucusu, bilgileri dosyanın farklı bölümlerinin bulunduğu yerlerde saklar.
- Birden çok G/ç düğümü dosyanın parçalarını saklar (PVFS, ext3 gibi temelde bulunan herhangi bir dosya sistemini kullanabilir).
Şekil 4. PVFS nasıl çalışır?
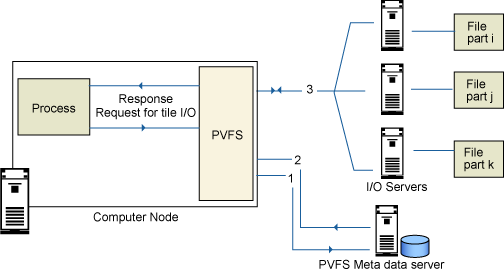
Bir kümedeki hesaplama düğümü, bu paralel dosya sistemindeki bir dosyaya erişmek istediğinde, aşağıdaki adımlardan geçer:
- Her zamanki gibi bir dosya isteğinde bulunur ve bu istek temelde bulunan PVFS dosya sistemine gider.
- PVFS, meta veri sunucusuna bir istek gönderir (Şekil 4'te 1. ve 2. adımlar); sunucu, istekte bulunan düğüme, dosyanın çeşitli G/ç düğümleri arasındaki yerini bildirir.
- Hesaplama düğümü bu bilgileri kullanarak ilgili tüm G/ç düğümleriyle iletişim kurup dosyanın tüm parçalarını alır (3. adım).
Bu işlemlerin tümü çağrıda bulunan uygulamaya açık bir şekilde gerçekleşir; tüm G/ç düğümlerine istekte bulunulmasının temelindeki karmaşıklık, dosyanın içeriğinin sıralanması, vb. gibi durumlar PVFS tarafından yönetilir.
PVFS'nin sağladığı bir avantaj, düzenli dosya sistemlerine yönelik ikili öğelerin değiştirilmeden çalışmasına izin vermesidir. Bu, paralel programlama alanında istisnai bir durumdur. (Kaynaklar bölümünde başka paralel dosya sistemlerinden de söz edilmektedir.)
Bilgi Edinme
- Kendi
kümenizi oluşturun:
- Building a Linux HPC Cluster with xCAT (IBM Redbook, Eylül 2002) sistem mimarlarına ve mühendislerine, küme teknolojisi hakkında temel bir yaklaşım edinme ve Linux Yüksek Performanslı Bilgiişlem (HPC) kümesinin kurulması konularında yol gösterir.
- Linux HPC Cluster Installation (IBM Redbook, Haziran 2001) Kuruluş ve yönetim için xCAT (xCluster Administration Tools) araçlarını konu alır.
- "Building an HPC Cluster with Linux, pSeries, Myrinet, and Various Open Source Software" (IBM Redpaper, Temmuz 2004) bir pSeries düğümleri topluluğunun ve bir Myrinet ara bağlantısının, gerçek bir HPC üretim işyükünün bir Linux kümelenmiş ortamında çalışabilmesine olanak verecek bir şekilde nasıl bir araya getirildiğini anlatmaktadır.
- "Build a heterogeneous cluster with coLinux and openMosix" (developerWorks, Şubat 2005) karışık ya da melez bir HPC Linux kümesinin nasıl oluşturulduğunu göstermektedir.
- Linux Clustering with CSM and GPFS (IBM Redbook, Ocak 2004) Linux kümeleri için Küme Sistemi Yönetimi ve Genel Paralel Dosya Sistemi konularını ele alır.
-
SETI
Project bağlantısına giderek SETI@home
hakkında bilgi edinebilirsiniz.
-
Protein katlanması hakkında daha fazla bilgi için
Folding@Home Project
bağlantısına giderek
protein
katlanmasına ilişkin genel bilgiler edinebilirsiniz.
-
IBM'in petrol ve diğer sanayilere yönelik hesaplama yoğunluklu
işlemlerin yönetilmesi için tasarladığı bilgiişlem merkezleri olan
Deep
Computing Capacity on Demand hakkında daha fazla bilgi
edinebilirsiniz.
-
John L. Gustafson'un re-evaluation
of Amdhal's Law (Amdhal Kanununun yeniden değerlendirilmesi)
konulu açıklamaları.
-
PVFS
kullanan ticari IDE diskleriyle nasıl gigabit/saniye G/ç işi
üretileceğine ilişkin bilgiler edinin.
-
"Build
a digital animation system" (developerWorks, Temmuz 2005) adlı
beş bölümlü yazı dizisi, profesyonel bir animasyon sistemi
çalıştırabileceğiniz bir HPC kümesini nasıl kuracağınızla ilgili
örnekler sunar.
-
developerWorks
Linux zone sayfasında Linux geliştiricilerine yönelik
kaynaklar yer alır.
-
Grid bilgiişlemle ilgili bilgi için
New to Grid
computing bağlantısına gidebilir ve developerWorks hakkındaki
Grid zone
sayfasını inceleyebilirsiniz.
Ürün ve teknoloji edinme
-
Bu bağlantıdan Parallel
Virtual Filesystem'ı yükleyebilirsiniz.
-
IBM alphaWorks'te, Linux kümelerini dağıtmak ve yönetmek
için kullanılan bir araç olan
xCAT
uygulamasını yükleyin.
-
Ücretsiz
SEK for Linux ürününü sipariş edin; bu ürün DB2®,
Lotus®, Rational®, Tivoli® ve WebSphere®
üzerinde Linux için en güncel IBM deneme yazılımlarını içeren ikili DVD
setidir.
-
Bir sonraki geliştirme projenizi Linux üzerinde oluşturmak için
IBM
deneme yazılımını doğrudan developerWorks sayfasından yükleyin.
Tartışma
-
developerWorks
blogs'a katılarak developerWorks topluluğuna
erişebilirsiniz.
Aditya Narayan, Kanpur'daki Indian Institute of Technology'de Fizik alanında lisans ve lisansüstü eğitim almıştır ve QCD Microsystems'i kurmuştur. Windows ve Linux'un iç işleyişi, WebSphere ve J2EE ve .NET gibi kurumsal platformlar konusunda uzmandır. Aditya çoğunlukla New York'ta yaşamaktadır. Aditya Narayan'a aditya_pda@hotmail.com adresinden erişebilirsiniz.










IBM dW kategorisi epey damardan bir kategori olmaya başladı.
Bu yazının 2. bölümü de yayınlandıktan sonra bir sonraki çeviri için önerileri almaya başlayalım.