|
Düzey: Başlangıç
Martin Streicher
(martin.streicher@linux-mag.com),
Şef Editör, Linux Magazine
07 Mart 2006
UNIX kabuğunun temellerini öğrenin ve sınırlı UNIX yardımcı
programları kümelerinden sayısız veri dönüştürmeleri oluşturmak için komut
satırını nasıl kullanabileceğinizi keşfedin.
UNIX Dilinde
Konuşma: Merhaba, kabuk
Bir UNIX® sisteminin en yeni ve farklı özelliklerinden biri
komut satırıdır. Biraz "birleştirici" (glue) ile birlikte birkaç tuş
vuruşuyla sınırlı UNIX yardımcı programı takımını, sayısız doğaçlama veri
dönüştürmelerine dönüştürmek için komut satırını kullanabilirsiniz.
Örneğin, geçerli çalışma dizininden başlayan klasör
hiyerarşisinde benzersiz dosya adları listesini bulmak için kabuk komut
satırına aşağıdakileri yazabilirsiniz:
find . -type f -print | sort | uniq
|
Bu komut satırı, üç ayrı yardımcı programı birleştirir:
-
find, adı belirtilen dizinin derinliklerini araştırır
-- bu durumda, . ya da nokta (geçerli çalışma dizininin
kısayolu) ile başlayan dosya sistemidir -- ve belirtilen ölçütlerle eşleşen tüm
girişlerin adlarını gösterir. Burada -type f,
find komutunu yalnızca düz dosyaları bulmak üzere
yönlendirir.
-
sort, adından da anlaşılacağı gibi bir listeyi
işler ve alfabetik olarak sıralanmış yeni bir liste görüntüler.
-
uniq ("unique" gibi okunur) bir listeyi tarar,
listedeki bitişik öğeleri karşılaştırır ve yinelenen öğeleri kaldırır. Örneğin,
listenizin aşağıdaki gibi olduğunu düşünelim:
Liste 1. Örnek liste
Groucho
Groucho
Chico
Chico
Groucho
Harpo
Zeppo
Zeppo
|
uniq komutu, liste öğelerini aşağıdaki şekilde
azaltır:
Liste 2. uniq komutu
Groucho
Chico
Groucho
Harpo
Zeppo
|
Ancak, özgün Marx Brothers listesi önce sıralansaydı (bir adın
tüm örneklerinin arka arkaya yeniden sıralanması) uniq komutu şu
sonucu verecekti:
Liste 3. uniq komutunun
çalıştırılması
Chico
Groucho
Harpo
Zeppo
|
find, sort ve uniq
komutlarının kapsamlı özellikleriyle ilgili ek bilgi almak için her bir
yardımcı programın UNIX sisteminizdeki man sayfasına bakın.
Veri girişi,
veri çıkışı, verilerle ilgili her şey
Bağımsız olarak kullanıldığında find, dosya
sisteminin içeriğini her zaman giriş verileri olarak alır. Ancak, hem
sort, hem de uniq komutu veri girişinin standart
giriş aygıtından (stdin) yapılmasını gerektirir. Genellikle standart
giriş klavye kullanılarak sağlanır: Örneğin, satırlarda sıralanmasını istediğiniz verileri
yazarsınız.
Varsayılan değer olarak find, sonuçları standart
çıkış aygıtında (stdout) (bu genellikle
uçbirim pencerenizdir) yazdırır. sort ve uniq,
sonuçları standart çıkış aygıtına yazdırır.
Standart giriş ve çıkışı göstermek için aşağıdaki metni uçbirim
pencerenize yazın (baştaki yüzde işaretinin [%] kabuk
komut isteminiz olduğunu düşünün):
Liste 4. stdin ve stdout
% sort
mustache
horn
hat
Control-D
|
sort komutu, standart giriş aygıtından yazdığınız üç
satırı okur, bunları sıralar ve sonucu standart giriş aygıtına yazar.
Şekil 1 içinde sort komutunun ve çoğu UNIX
komut satırı yardımcı programlarının komut satırından çalıştırılmasına ilişkin
kavramsal bir resim sunulmuştur.
Şekil 1. Stdin'den okuyan ve stdout'a
yazan tipik bir UNIX komut satırı yardımcı programı
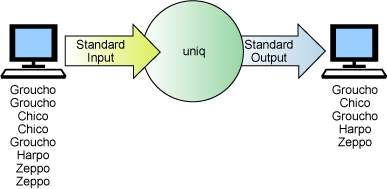
find gibi bazı yardımcı programlar verileri stdin'den
okumaz. Bunun yerine, işlemeleri gereken verileri, dosya sistemi ya da sistem
çekirdeği gibi sistem kaynaklarından okurlar ve sonuçları stdout'ye yazarlar.
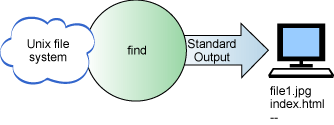
find komutunun nasıl çalıştığını görmek için aşağıda
Şekil 2'ye bakın.
Şekil 2. Bazı yardımcı programlar
verileri sistem kaynaklarından okurlar ve stdout'ye yazarlar
Stdin ve stdout'un kullanılmasına ek olarak UNIX komutları,
tanılama için ayrılmış (uzlaşma ile; zorunlu değildir) özel bir çıkış noktasına
hata iletilerini gönderebilirler. Çıkış noktasına standart hata aygıtı
(genellikle stderr) denir. Şekil 3 içinde bir yardımcı
programın çalıştırıldığı basit bir komut satırını görebilirsiniz.
Şekil 3. UNIX komutları hataları özel bir
kanala gönderir, standart hata
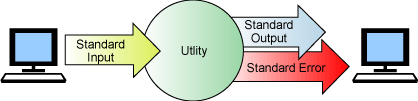
Şekil 3 içinde gösterilen şekilde, çoğu UNIX
komutu girişleri uçbirimden okur, sonuçları uçbirime gönderir ve hataları
uçbirime yazdırır. Varsayılan değer olarak ve siz, tersi bir durumu
belirtmediğiniz sürece, uçbiriminiz stdin için veri kaynağı, stdout ve stderr
için de hedef olarak kullanılır.
Akışın
yönlendirilmesi
Ancak, stdin kaynağını ve stdout ve stderr'nin son hedeflerini
değiştirebilirsiniz. Stdin'i, verileri bir metin dosyasından, bir aygıttan
(bilgisayara bağlı bir probe'dan) ya da bir ağ bağlantısından okumaya
zorlayabilirsiniz. Benzer bir şekilde, çıkışı bir dosyaya, bir aygıta ya da bir
bağlantıya gönderebilirsiniz. Her şeyin bir dosya olduğu UNIX'te, bir kaynağı
ya da hedefi oluşturmak, başka bir kaynağı ya da hedefi kaldırmak ya da
oluşturmak kadar kolaydır.
Bir işlemin verilerinin kaynağını ve hedefini değiştirmeye
yeniden yönlendirme denir. Stdin'i, bir dosyadan ya da başka bir kaynaktan
veri okuması ve stdout ve stderr'yi (ayrı olarak), verileri uçbirim
penceresinden farklı bir yere yazmak için yeniden yönlendirebilirsiniz.
Yukarıda gösterilen özgün find komutu gibi birçok durumda,
yardımcı programları da diğer yardımcı programlardan ve diğer yardımcı
programlar için veri tüketmek ve üretmek üzere yeniden yönlendirebilirsiniz.
Dikey çubuk (|) karakterinin amacı budur. Bir komutta, bir
komutun verilerini sonraki komuta göndermek için, bakır boru parçalarının suyu
su ısıtıcınızdan musluğunuza getirdiği gibi, dikey çubukları kullanarak siz de
işlemleri birbirine zincirleme bağlayabilirsiniz.
Şekil 4 içinde find . -type f -print |
sort | uniq komutunun kavramsallaştırılması gösterilmektedir.
Şekil 4. Dikey çubuklarla birbirine
bağlanmış üç yardımcı programın kavramsal bir modeli
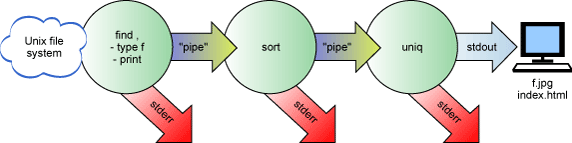
find komutunun stdout'u uniq komutunun
stdin'i ve uniq komutunun stdout'u sort komutunun
stdin'i olur. Son olarak, sort, sonuçları uçbirime bağlı kalan
standart çıkış aygıtına yazdırır. Komutların stderr'si yeniden yönlendirilmez;
bu nedenle, üç yardımcı program da hata iletilerini uçbirime yazdırır. (Üç
yardımcı programın hata iletileri karışık kullanılır, ancak iletilerin sırası
doğru olur.)
Gerekirse, yukarıda gösterilen ardışık işlemi daha da
genişletebilir ve uniq yardımcı programının çıkışını başka bir
yardımcı programa yeniden yönlendirebilirsiniz. Dönüştürmeyi daha da
genişletmek için yeni bir dikey çubuk eklemeniz yeterlidir. Örneğin,
less yardımcı programını kullanarak çıkışı sayfalandırmak için
| less ya da benzersiz dosya adlarının sayısını bulmak için
| wc -l komutunu ekleyebilirsiniz. (wc, sözcük
sayısının kısaltmasıdır; wc, karakterleri, sözcükleri ve
satırları sayabilir.)
Buna alternatif olarak, tüm sıranın çıkışını bir dosyaya kaydetmek
için > karakterini kullanabilirsiniz (varsa, dosyanın var olan
içeriği ortadan kaldırılır). Sonuçları var olan bir dosyaya eklemek için
>> karakterini de kullanabilirsiniz.
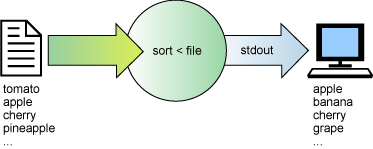
Başka bir yararlı yeniden yönlendirme <
karakteridir. Şekil 5 içinde, stdin'nin verileri bir
dosyadan okumak için nasıl yeniden yönlendirebileceği gösterilmektedir.
sort komutu, adı belirtilen bir dosyadan bir sözcük listesini okur
ve alfabetik sırayla bu listeyi düzenler.
Şekil 5. Standart girişin verileri bir
dosyadan okuyacak şekilde yeniden yönlendirilmesi
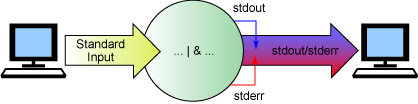
Genellikle stdout ve stderr'yi yakalamak istersiniz. Örneğin,
büyük bir veri toplama görevi çalıştırıyorsanız, geçici çıkışı ve yürütme
sırasında ortaya çıkmış hataları gözden geçirmek isteyebilirsiniz. Bunu yapmak
için yeniden yönlendirme sözdiziminin değişkenlerini kullanabilirsiniz:
|&, >&, >>&,
dikey çubuk, eşzamanlı olarak stdout'u oluşturur ve stderr'yi ekler.
Şekil 6'da bir çıkış akışında stdout ve stderr'nin nasıl
birleştirildiği gösterilmektedir.
Şekil 6. Standart giriş ve standart hata
aygıtlarının birleştirilmesi
Z kabuğuna giriş
Modern UNIX kabuklarının çoğu -- Bourne kabuğu (bash)
ve Korn kabuğu (ksh) dahil -- burada belirtilen yeniden
yönlendirmeleri destekler, ancak bu kabukların her ikisi için gerekli özel
sözdizimi biraz farklı olabilir. (Özellikler için kabuk belgelerinizi denetleyin.)
Yeniden yönlendirme işleçlerinin çoğu, en az 25 yıldır tüm UNIX
kabuklarında kullanılan tutarlı özelliklerdir. Ancak, bu kabukların çoğu
yeniden yönlendirme için yeni zemin oluşturma ve yeniden yönlendirmeyi uygulama
açısından yeni yollar keşfetme konusunda başarısız olmuştur. Örneğin,
kabukların çoğu yalnızca tek bir dosyanın girişini yeniden yönlendirebilir ve
çıkışı birden çok hedefe yönlendirmek için tee gibi bir yardımcı
program kullanmanız gerekir. (Tesisatçıların kullandığı T bağlantı parçası gibi
tee'nin bir giriş ve iki çıkışı vardır.) Aşağıda, kabuk (komut
satırı yorumcusu) olarak bash kabuğunun kullanıldığı bir örnek
gösterilmiştir:
Liste 5. bash örneği
bash$ ls
tellme
bash$ cat tellme
echo Your current login, working directory, and system are...
whoami
pwd
systemname
bash$ bash < tellme |& tee log
Your current login and working directory are...
strike
/home/strike
bash: systemname: command not found
bash$ ls
tellme log
bash$ cat log
Your current login and working directory are
strike
/home/strike
bash: systemname: command not found
|
UNIX kabukları yüksek oranda özelleştirilmiştir ve genellikle
klavye ile etkileşimli bir şekilde kullanılır; ancak, bash gibi
bir kabuk da girişi bir dosyadan okuyabilir. (Sonuçta, stdin yalnızca bir
dosyadır.) Önceki ufak parçada, bash < commands sözcük grubu,
bash komutunun tellme dosyasında bulduğu komut listesini
yürütmesini sağlar. |&tee log sözcük grubu, bash
komutunun stdout ve stderr'sini, stdin'ini stdout'u ve dosya günlüğüne
yazdıran tee yardımcı programına bağlar.
Peki, bash kabuğunun birden fazla giriş dosyasını
işlemesini isterseniz ne olacak? Belki de çalışacak tek çözüm cat file1
file2 file3 | bash olacaktır; çünkü bash, bash <
file1 < file2 < file3 gibi bir sözdizimini desteklemez.
Bununla birlikte, bash, çıkışı birden fazla hedefe
yeniden yönlendirmez. Örneğin, bash komut satırından
bighairyscript > ~/log | mail -s "Important stuff" team gibi
bir yönerge giremezsiniz.
Ancak, nispeten yeni bir kabuk olan Z kabuğu
(zsh; bkz. Kaynaklar), aynı komut
satırında birden çok giriş ve çıkış yeniden yönlendirmesini işleyebilir.
Örneğin, aşağıda stdout'u log (günlük) adlı bir dosyaya kaydeden ve bunu,
e-posta ile size gönderen bir komut gösterilmiştir:
Liste 6. Z kabuğu
zsh% bash < tellme > log | mail -s "Who you are" 'whoami'
bash: line 4: systemname: command not found
zsh% <log
Your current login, working directory, and system are...
strike
/home/strike
|
('whoami' sözcük grubu, whoami komutunu
çalıştırır ve bu komutun sonucunu, sözcük grubunun yerine yerleştirir. Komut
satırının geri kalanını çalıştırmadan önce küçük bir kabuk komutunu
çalıştırmaya benzer.)
Önceki komutu soldan sağa doğru gözden geçirelim.
bash komutu, log dosyasını oluşturur ve tellme içinde bulunan
komutların stdout'unu size postalar. Stderr, > ya da dikey çubuk
karakteriyle yeniden yönlendirilmediğinden, hata iletileri stdout'a
yazdırılır. <log komutu, başka bir Z kabuğu kısaltmasıdır;
cat ile aynıdır. (Ve evet, > file komutu cat
> file komutu ile aynıdır.)
Z kabuğu birden çok giriş yeniden yönlendirmesini de
işleyebilir. cat < file1 < file2 < file3 Z kabuğu komut
satırı, cat file1 file2 file3 ile aynıdır. Kuşkusuz, önceki
sözdizimi ikincisinden daha hantaldır ve genellikle, birden çok stdout yeniden
yönlendirmesi daha sık kullanılır. Ancak, çalıştırmak istediğiniz yardımcı
program birden çok giriş bağımsız değişkenini kabul etmiyorsa, Z kabuğunun
birden çok girişi yeniden yönlendirmesi işe yarayabilir.
Z kabuğu, daha iyi globbing (genel arama karakteri
eşleştirmeleri), gelişmiş kalıp eşleştirmeleri ve komut satırına yazmanız
gerekenleri en alt düzeye indiren kapsamlı otomatik tamamlama sistemini de
içeren diğer yeni inceliklerle doludur. Bu dizinin sonraki iki makalesinde Z
kabuğuyla ilgili daha ayrıntılı bilgi verilecektir.
Kabukla ilgili
incelikler
Kesinlikle daha üretken bir şekilde çalışmanızı sağlayacak bazı
güçlü komut satırı birleşimlerini aşağıda bulabilirsiniz. Komutlar yalnızca
zsh içinde değil tüm kabuklarda çalışır.
-
tar ile herhangi bir dizininin simgesel
bağlantıları da içeren bire bir kopyasını oluşturun:
tar cf - /path/to/original | \
(mkdir -p /path/to/copy; cd /path/to/copy; tar xvf -)
|
İlk tar, /path/to/original dizinini arşivler ve
stdout'a arşiv dosyasını gönderir; oluşturma (c) seçeneğiyle
kullanılan tire (-) işareti stdout'u belirtir. Parantez içindeki
komut bir alt kabuktur: Alt kabuktaki komutlar, geçerli kabuğun ortamını
etkilemez. mkdir -p komutu, oluşturulması gereken ara dizinlerle
birlikte adlandırılan dizini oluşturur ve cd komutu yeni dizine
geçilmesini sağlar. İkinci tar, stdin'den bir arşivi okur ve
yerinde açar; ayıklama (x) seçeneğiyle kullanılan tire işareti
stdin'e başvurur.
-
Bir komut sırasının stdout'unu kaydetmek ve aynı zamanda
görüntülemek için less -O file komutunu kullanın.
-O seçeneği, stdin'i adlandırılan file
dosyasına kopyalar. Aşağıdaki örneği inceleyin:
sort /etc/aliases | less -Osorted
|
-
Bir dizinde binlerce dosya bulunuyorsa, kabuğunuz
(zsh dahil, dosyaların sayısına ve adlarına bağlı olarak) tüm
dosyaları genel arama karakteri eşleştirmelerini kullanarak
numaralandıramayabilir; çünkü, komut satırı genellikle belirli sayıda
karakterle sınırlandırılmıştır. Bu nedenle,
gibi kabuk komut dosyası sözcük grupları başarısız olabilir.
(Komut satırınızın uzunluğunu geçtiğinizde, Satır uzunluğu aşıldı
gibi bir ileti görebilirsiniz.) Böyle bir hata ortaya çıkarsa, bir dikey çubuk
karakteri ve xargs yardımcı programını kullanın.
xargs, verileri bir dikey çubuktan okur ve okunan her bir satır için
belirli bir komutu çalıştırır.
Örneğin, www.example.com sitesine başvuran sunucunuzdaki tüm
Web sayfalarını bulmak için aşağıdaki komut satırını kullanabilirsiniz:
% find / -name '*html' -print \
| xargs grep -l 'www.example.com' \
| less -Opages
|
xargs, find komutundan dosya
adlarını kullanır ve her dosyayı işlemek için yeniden grep -l
komutunu çalıştırır; adlandırılan dosyaların sayısı önemli değildir. (Bir
eşleşme bulunduğunda, grep -l dosyanın adını yazdırır ve bu
dosyada, daha fazla eşleştirme yapmaz.) less, sonuçları sayfalara
bölmenizi sağlar ve listeyi, adı belirtilen dosyanın sayfalarına
kaydeder. Sonuçta, "www.example.com" dizesini içeren dosya adlarından oluşan
bir liste ortaya çıkar.
Yolculuk
başlıyor
Bu makalede, UNIX kabuğunun temellerini öğrendiniz. Sonraki
makalelerde, komut satırı araçları ve kendi yönetiminizdeki teknikler
daha ayrıntılı olarak incelenecektir. Dosya sistemlerinden tüm yerel ağlara kadar, hemen
hemen tüm bilgiler ve sistem yönetimi, UNIX komut satırından verimli bir
şekilde kullanılabilir.
Bizi izlemeye devam edin!
Kaynaklar Bilgi Edinme
- UNIX
Dilinde Konuşma Bu dizinin diğer bölümlerini de inceleyin.
zsh posta
listesi arşivi: Z kabuğu incelikleri ve ipuçlarıyla ilgili daha fazla bilgi
için bu listeyi okuyun.
- AIX ve UNIX:
Daha ayrıntılı bilgi ister misiniz? developerWorks AIX ve UNIX alanı, bilgi içerikli
yüzlerce makaleyi ve giriş düzeyindeki, orta ve ileri düzeydeki öğreticiyi
içerir.
- developerWorks
teknik etkinlikler ve web yayınları: Güncel developerWorks teknik etkinliklerini ve web
yayınlarını izleyin.
- Podcasts: İlgili
ayarları yapın ve IBM teknik uzmanlarının bilgilerine ulaşın.
Ürün ve teknoloji edinme
Tartışma
Yazar
hakkında
|
Martin Streicher, Linux Magazine adlı dergide Şef
Editör'dür. Purdue University'den bilgisayar bilimi konusunda master derecesi
almış ve 1982 yılından bu yana UNIX benzeri sistemlerde Pascal, C, Perl, Java
ve (en son) Ruby programlama dillerinde programlama yapmaktadır.
|
|







