
Yüksek performanslı Linux kümeleme, 2. Bölüm: Çalışan bir küme oluşturma
Paralel programlar yazma ve sisteminizi yapılandırma
Düzey: Orta
Aditya
Narayan
(aditya_pda@hotmail.com),
QCD Microsystems Kurucusu
27 Ekim 2005
Yüksek Performanslı Bilgiişlemin (HPC) kolaylaşmasının nedenlerinden biri açık kaynak yazılım kavramlarının kullanılmaya başlanması, bir başka nedeni ise kümeleme teknolojisinin iyileştirilmesidir. Sunulan iki makaleden ikincisi olan bu yazı, MPI kullanılarak yapılan paralel programlama işlemlerini ele alır ve küme yönetimi ve karşılaştırmalı sınamasıyla ilgili genel bilgiler sunar. Ayrıca, sağlam kümeler oluşturmak için bir açık kaynak projesi olan OSCAR kullanılarak nasıl Linux® kümesi oluşturacağınızı gösterir.
Bu yazı dizisinin Kümeleme ilkeleri başlıklı 1. Bölümünde küme türleri, kümelerin kullanım alanları, HPC ilkeleri ve kümeleme teknolojisinin Yüksek Performanslı Bilgiişlemde gelişmesinin nedenleri ele alınır.
Bu makalede paralel algoritmalar ele alınır ve paralel program yazma, küme oluşturma, kümeler için karşılaştırmalı değerlendirme işlemlerinin nasıl yapıldığı gösterilir. MPI kullanılarak paralel programlama yapılması ve Linux kümesi oluşturmakla ilgili temel bilgilere göz atacağız. Bu makalede, sağlam kümeler oluşturmanıza yardımcı olan bir açık kaynak projesi olan OSCAR'la tanışacağız. Ayrıca, küme yönetimi ve karşılaştırmalı değerlendirme kavramlarına göz attıktan sonra bir kümede standart LINPACK testleri yapmak için gerekli adımlarla yazımızı bitireceğiz.
Linux'u kurduysanız, bu makaleyi okuduktan sonra bir Linux kümesi için kuruluş ve sorun giderme işlemlerini gerçekleştirebilirsiniz. Aşağıdaki Kaynaklar bölümündeki yararlı bağlantıları kümeleme hakkında daha fazla bilgi edinmek için kullanabilirsiniz.
Kümeleme ve paralel programlama platformları
1. Bölüm'de gördüğünüz gibi, HPC genellikle paralel programlamayla ilgili bir kavramdır. Paralel programlama oldukça yerleşmiş bir alandır ve bu alanın çevresinde, son 20 yılda birçok programlama platformu ve standardı gelişmiştir.
HPC'de en çok kullanılan iki donanım platformu paylaşılan bellek sistemleri ve dağınık bellek sistemleridir. Ayrıntılar için 1. Bölüm'e bakın.
Paylaşılan bellek sistemlerinde, Yüksek Performaslı FORTRAN, paralel programlama için geliştirişmiş bir dildir. Bu dil, paralel verilerden yararlanır ve yönergeleri farklı işlemcilerdeki bir dizinin farklı dizinlerinde yürüterek tüm diziler üzerinde aynı anda hareket edebilir. Böylece, paralel duruma getirme işlemleri sizin uğraşmanıza gerek kalmadan otomatik olarak gerçekleşir. (Örnek olarak sunabileceğimiz, Jamaica projesinde, standart bir Java programı, birden çok iş parçacıklı kod üretmek için özel bir derleyici kullanılarak yeniden çarpanlara ayrılır. Üretilen kod, otomatik olarak SMP mimarisinden yararlanır ve paralel olarak çalışır.)
Dağınık bellek sistemlerinde, durum çok farklıdır çünkü bellek dağıtılmıştır; yazacağınız kodda, temel donanımın dağınık yapısı dikkate alınmalı ve farklı düğümler arasında ileti alışverişi yapmak için açık ileti geçişi kullanılmalıdır. Bu nedenle, bir zamanlar en çok kullanılan paralel programlama platformu Paralel Sanal Makinelerdi (PVM); ancak, son zamanlarda kümeler için paralel programlar yazmak amacıyla kullanılan gerçek standart MPI olmuştur.
Linux için yüksek kalitede MPI uygulamaları FORTRAN, C ve C++ için ücretsiz edinilebilir. En çok kullanılan iki MPI uygulaması şunlardır:
- MPICH
- LAM/MPI
Bu makalenin ilerideki bölümlerinde MPICH tabanlı bir Linux kümesi oluşturacak ve MPI tabanlı bir program örneğine göz atacağız.
Basit bir Linux kümesi yaratma
Kümelemenin en ilginç taraflarından biri, Linux'la ilgili temel kuruluş ve sorun giderme becerilerine sahip olduğunuzda, Linux tabanlı kümeleri kolaylıkla oluşturabilmenizdir. Şimdi bunun nasıl yapıldığını görelim.
Bizim kümemiz için MPICH ve bir dizi standart Linux iş istasyonu kullanacağız. Kolaylık olması ve temel ilkelerin daha iyi vurgulanması amacıyla, yalnızca, kümelenmiş bir ortamda paralel program çalıştırabileceğiniz sade minimum sistemi kuracağız.
Bu bölümde yer alan yedi adımda, sistemimizin iskeletinin nasıl oluşturulduğu gösterilir. Sağlam kümeler oluşturmak ve bunları yönetmek için daha çok çaba gerekir, bu konular makalenin daha sonraki bölümlerinde ele alınacaktır.
Gerçek bir küme için en az iki adet Linux makinesi gereklidir. Ayrıca, iki VMware görüntüsü de çok işe yarar. (Tabii VMware'in performansa katkısı olmasını beklemeyin. Aslında, CPU paylaşılacağından kesinlikle bir performans artışı olacaktır.) Bu makinelerin adlarını kullanarak birbirleriyle ping iletişimi kurabildikleriden emin olun. Ping işlemi gerçekleşmezse, /etc/hosts içine gerekli girişleri ekleyin.
GNU derleyicisini ve GNU FORTRAN derleyicisini kurun.
SSH'yi tüm düğümleriniz için komutları parola istemeden yürütecek
şekilde yapılandırın. Amacımız, parola istenmeden çalışabilmek için
ssh -n host whoami gibi bir değer elde etmektir. SSH,
farklı makineler arasında iletişim kurmak için kullanılacaktır. (Ayrıca,
rsh de bu amaçla kullanabilir.)
ssh-keygen -f /tmp/key -t dsa, key adında bir dosyada
bir özel anahtarla key.pub adında bir dosyada bir genel anahtar
verir.
Kümenizi kök olarak oluşturuyorsanız ve programlarınızı kök olarak çalıştıracaksanız (tabii bunu yalnızca deneme sırasında yapın), kümenizdeki tüm düğümlerde, özel anahtarı /root/.ssh/identity dosyasına, genel anahtarı da /root/.ssh/authorized_keys dosyasına kopyalayın.
Herşeyin düzgün işlediğini denetlemek için şu komutu
çalıştırın: ssh -n hostname 'date' ve komutun hatasız
çalıştığını doğrulayın. Emin olmak için bunu tüm düğümlerde test
etmelisiniz.
Not: Güvenlik duvarınızı düğümlerin birbiriyle iletişim kurmasına izin verecek şekilde yapılandırmanız gerekebilir.
Şimdi MPICH kuruluşunu yapacağız. anl.gov Web sitesinden MPICH'nin UNIX sürümünü yükleyin (bağlantı için Kaynaklar bölümüne bakın). Aşağıda hızlı bir genel bakış sunulmuştur.
mpich.tar.gz in /tmp dosyasını yüklediğinizi varsayalım:
cd /tmp
tar -xvf mpich.tar.gz (Bunun sonucunda /tmp/mpich-1.2.6 adlı bir dizin
oluşturulduğunu varsayalım)
cd /tmp/mpich-1.2.6
./configure -rsh=ssh -- Bu komut, MPICH'ye iletişim
mekanizması olarak ssh'yi kullanmasını belirtir.
make -- Bu adımın sonunda, MPICH kuruluşunuz kullanıma hazır olur.
MPICH'nin tüm düğümlerinizden haberdar olması için /tmp/mpich-1.2.6/util/machines/machines.LINUX dosyasını düzenleyin ve tüm düğümlerin anasistem adlarını bu dosyaya eleyerek MPICH kuruluşunuzun tüm düğümlerinizden haberdar olmasını sağlayın. Daha sonraki bir aşamada düğüm eklediğinizde de bu dosyayı düzenleyin.
/tmp/mpich-1.2.6 dizinini kümenizdeki tüm düğümlere kopyalayın.
Examples dizininde birkaç test programını çalıştırın:
cd /tmp/mpich-1.2.6/utils/examplesmake cpi/tmp/mpich-1.2.6/bin/mpirun -np 4 cpi-- MPICH'ye bunu dört işlemcide çalıştırmasını belirtir; kurulumunuzda dörtten az işlemci varsa, endişelenmeyin; MPICH fiziksel donanımın eksikliğini telafi edecek işlemler yaratacaktır.
Kümeniz hazırdır! Gördüğünüz gibi, tüm zor işlemler MPI uygulaması tarafından yapılmaktadır. Daha önce de belirtildiği gibi, bu bir küme iskeletidir ve büyük bölümü makinelerin birbiriyle iletişim kurmasını sağlayarak yapılan manüel işlemlere dayanır (ssh yapılandırılır, MPICH manüel kopyalanır, vb.).
Açık kaynak kümesi uygulama kaynakları
Açıkça görüldüğü gibi, yukarıdaki kümeyi sağlamak zor olacaktır. Dosyaları her bir düğüme kopyalamak, SSH ve MPI'yı eklenen her düğümde ayarlamak, bir düğüm kaldırıldığında gerekli değişiklikleri yapmak, vb. gibi işlemleri gerçekleştirmek çok basit değildir.
Açık kaynak kaynakları güçlü üretim kümelerini oluşturmanıza ve yönetmenize yardımcı olabilir. OSCAR ve Rocks bunlara örnektir. Küme yaratırken yaptığımız birçok işlem bu programlar tarafından otomatik bir şekilde gerçekleştirilmiştir.
Şekil 1, basit bir kümenin şemasıdır.
Şekil 1. Basit örnek küme
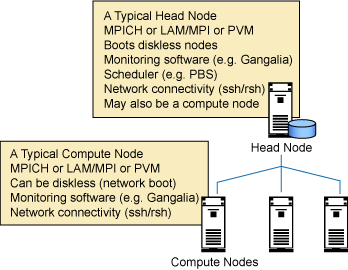
OSCAR, PXE (Portable Execution Environment) kullanılarak otomatikleştirilmiş Linux kuruluşlarını da destekler. Ayrıca, OSCAR aşağıdaki işlevlere de yardımcı olur:
- Hesaplama düğümlerine otomatik Linux kuruluşu
- DHCP ve TFTP yapılandırması (PXE kullanılarak Linux kuruluşu).
Birçok yeni bilgisayarda makineyi DHCP sunucusu kullanarak
önyüklemeyi sağlayan bir BIOS bulunur. BIOS'ta bulunan yerleşik bir
DHCP istemcisi, kendisine TFTP kullanılarak DHCP sunucusundan
aktarılan bir işletim sistemi görüntüsü ister. Bu Linux görüntüsü
OSCAR tarafından yaratılır; ayrıca, DHCP ve TFTP kuruluşu
ve yapılandırması da OSCAR tarafından yürütülür.
- SSH yapılandırması.
- Otomatik NFS kuruluşu.
- MPI kuruluşu ve yapılandırması (MPICH ve LAM/MPI).
- PVM kuruluşu ve yapılandırması (MPI yerine PVM kullanmak
isterseniz).
- Ana düğüm ve hesaplama düğümleri arasında özel alt ağ
yapılandırması.
- Kümeye iş gönderen birçok kullanıcının otomatik yönetimi için
zamanlayıcı (Open PBS ve Maui) kuruluşu.
- Performans izlemesi için Ganglia kuruluşu.
- Düğüm ekleme/kaldırma için hazırlık.
OSCAR şu anda birkaç Red Hat Linux sürümünü desteklemektedir; desteklenen diğer dağıtımlar için OSCAR Web sitesini ziyaret edin (bağlantı için Kaynaklar bölümüne bakın). Kuruluş sırasında ortaya çıkan hatalara göre, komut dosyalarından bazılarını ayarlamanız gerekebilir.
OSCAR'ı kullanarak Linux kümesi yaratma
Şimdi OSCAR kaynaklarıyla başlayıp tüm işlevlere sahip bir küme oluşturalım. Elinizde ağ bağlantısı olan iki ya da daha çok standart iş istasyonunuz olduğunu varsayalım. Bunlardan birini ana düğüm, diğerlerini hesaplama düğümü yapalım.
Linux kümesini oluştururken yaptığımız gibi, ana düğüm üzerinde gerçekleştirilecek adımların üzerinden geçeceğiz. OSCAR, işletim sistemi kuruluşu dahil, diğer tüm düğümleri otomatik olarak yapılandırır. (OSCAR kuruluş kılavuzuna bakın; aşağıda kuruluş işlemine kavramsal bir genel bakış sunulmuştur.)
Linux'u ana düğüme kurun. Bir X sunucusu da kurun.
mkdir /tftpboot, mkdir /tftpboot/rpm. Tüm RPM'leri
kuruluş CD'sinden bu dizine kopyalayın. Bu RPM'ler istemci görüntüsü
oluşturmak için kullanılır. Aslında tüm RPM'ler gerekmeyecektir ancak
görüntüyü otomatik olarak oluşturmak için bunları bulundurmakta yarar
vardır.
MySQL'in kurulmasını ve doğru biçimde yapılandırılmasını ve MySQL'e Perl'den erişebilmenizi sağlar; çünkü OSCAR tüm kuruluş bilgilerini MySQL'de saklar ve bunlara erişmek için Perl'i kullanır. Bu adım genellikle isteğe bağlıdır ve OSCAR tarafından gerçekleştirilir, ancak, bazen başarısız olur (özellikle OSCAR'ı desteklenmeyen bir dağıtıma kuruyorsanız)
OSCAR kaynaklarını yükleyin ve derleyin:
configure
make install
OSCAR sihirbazını başlatın. Kümenin küme düğümleri arasındaki
bağlantılar için eth1 kullanmasını istediğinizi varsayarsak
şunu kullanın: /opt/oscar/install_cluster eth1.
Bu aşamada, OSCAR ekranlarını adım adım izleyin. Adımları doğru sırada gerçekleştirin:
- OSCAR kuruluşunuzu özelleştirmek için paketler seçin. Bu
paketler hakkında bilgi sahibi değilseniz, şimdilik bu adımı
atlayın.
- OSCAR paketlerini kurun.
- İstemci görüntüsünü oluşturun. Bu görüntü, hesaplama düğümleri tarafından kullanılacaktır.
- OSCAR istemcilerini tanımlayın. Bu, hesaplama düğümlerini tanımlar. Kullanmak istediğiniz düğüm sayısını ve bunların kullanacağı alt ağı belirlemeniz gerekir. Kaç tane düğüm olması gerektiğinden emin değilseniz bunu daha sonra değiştirebilirsiniz.
- Farklı düğümlerin MAC adreslerini IP adresleriyle eşleyin. Bu adım için, her düğümün BIOS içindeki PXE ağ önyükleme seçeneği kullanılarak önyüklenmesi gerekir.
Son olarak, testleri çalıştırın. Herşey yolunda giderse, her test başarıyla sonuçlanır. Bazen hiçbir şey yanlış olmasa da testler ilk denemede başarısız olur. Testleri her zaman, /opt/oscar dizinindeki komut dosyalarını el ile çalıştırarak yürütebilirsiniz.
Şimdi yeni düğümler eklemek istiyorsanız, OSCAR sihirbazını yeniden başlatın ve düğümleri ekleyin. Linux işletim sistemi bu düğümlere PXE kullanılarak OSCAR tarafından otomatik olarak kurulur.
Artık küme hazırdır, paralel programları çalıştırabilir, gerektiği kadar yeni düğüm ekleyebilir ya da düğümleri kaldırabilir ve Ganglia ile durumu izleyebilirsiniz.
Geniş bir kullanıcı tabanı olan bir üretim ortamındaki bir kümeyi yönetmek söz konusu olduğunda, iş zamanlaması ve izleme çok önemlidir.
MPI çeşitli düğümlerdeki işlemleri başlatacak ve durduracaktır ancak bu tek bir programla sınırlıdır. Tipik bir kümede, birçok kullanıcı programlarını çalıştırmak isteyecektir; bu nedenle, kümenin verimli bir şekilde kullanılmasını sağlamak için zamanlama yazılımı kullanmalısınız.
Çok kullanılan zamanlama sistemlerinden biri olan OpenPBS, OSCAR tarafından otomatik olarak kurulur. Bununla kuyruklar yaratıp bu kuyruklara işler gönderebilirsiniz. OpenPBS içinde, gelişmiş iş zamanlama ilkeleri de yaratabilirsiniz.
Ayrıca, OpenPBS yürütülen işleri görüntülemenizi, işleri göndermenizi ve iptal etmenizi de sağlar. Belirli bir iş tarafından kullanılabilecek maksimum CPU süresini denetleyerek sistem yöneticilerine kolaylık sağlar.
Küme yönetiminin önemli bir yanı izlemedir; özellikle de kümenizde çok fazla sayıda düğüm varsa bu daha da önem kazanır. Ganglia (OSCAR ile birlikte gönderilir) ve Clumon gibi birkaç seçenekten yararlanabilirsiniz.
Ganglia, Web tabanlı bir ön uca sahiptir ve CPU ve bellek kullanımı için gerçek zamanlı izleme sağlar; herhangi bir işlemi izleyecek şekilde kolaylıkla genişletilebilir. Örneğin, basit komut dosyalarıyla Ganglia'nın CPU sıcaklığı, faz hızı, vb. konularda bilgi vermesini sağlayabilirsiniz. Sonraki bölümlerde, bazı paralel programlar yazacağız ve bunları küme üzerinde çalıştıracağız.
Paralel programlamanın, temel donanımdan yararlanan kendi paralel algoritmaları vardır. Şimdi bu tür bir algoritmaya bakalım. Bir düğümde toplanacak bir dizi N tamsayısı olduğunu varsayalım. Bu toplamayı normal yoldan yapmak için gerekli süre O(N) kadardır (100 tamsayıyı toplamak 1ms zaman alırsa, 200 tamsayıyı toplamak 2ms zaman alır ve bu şekilde devam eder).
Bu sorunun doğrusal olarak ölçeklenmesine geçmek zor görünebilir, ancak çok kullanışlı bir yolu vardır. Bir programın dört düğümlü bir kümede çalıştığını, her düğümün belleğinde bir tamsayı olduğunu ve amacın bu dört sayıyı toplamak olduğunu düşünelim.
Aşağıdaki adımları inceleyelim:
- Düğüm 2, tamsayısını düğüm 1'e, düğüm 4 ise tamsayısını düğüm 3'e gönderir. Böylece düğüm 1 ve 3'te ikişer tamsayı olur.
- Bu iki düğümdeki tamsayılar toplanır.
- Bu kısmi toplam düğüm 3 tarafından düğüm 1'e gönderilir. Böylece düğüm 1'de iki kısmi toplam olur.
- Düğüm 1 son toplamı elde etmek için bu kısmi toplamları toplar.
Gördüğünüz gibi, başlangıçta 2N sayısı olsaydı, bu yaklaşımla bunlar ~N adımda toplanacaktı. Bu nedenle, algoritmanın ölçeği O(log2N) kadardır; bu, ardışık örneğe göre O(N) değerinin üzerinde bir gelişmedir. (128 sayıyı toplamak 1ms alıyorsa, bu yaklaşımla 256 sayıyı toplamak (8/7) ~ 1.2ms alır. Ardışık yaklaşımda, bu süre 2ms olurdu.
Bu yaklaşım her adımdaki hesaplama düğümlerinin yarısını da
serbest bırakır. Bu algoritma yineleyen ikiye bölme ve
ikiye katlama olarak bilinir ve birazdan ele alacağımız, MPI'deki
azaltma işlevi çağrıları sınıfının temelinde yatan
mekanizmadır.
Paralel algoritmalar, paralel programcılıktaki birçok pratik soruna yöneliktir.
Paralel programlamada bir matrisi bir vektörle çarpmak için MPI'yı kullanma
Artık paralel programcılık platformunun ilkelerini öğrendiniz ve hazır bir kümeniz oldu; şimdi kümenin avantajından yararlanan bir program yazalım. Konuya ısınma aşamasını atlayıp doğrudan asıl konuya geçelim ve iki matrisi çarpmak için MPI tabanlı bir program yazalım.
Bu sorunu çözmek için paralel algoritmalar bölümünde anlatılan algoritmayı kullanacağız. Diyelim ki, bir vektörle çarpmak istediğimiz bir 4X4 matrisi var (bir 4X1 matrisi). Standart matris çarpma tekniğinde biraz değişiklik yaparak önceki algoritmanın buraya uygulanabilmesini sağlayacağız. Bu teknik için Şekil 2'ye bakabilirsiniz.
Şekil 2. Matrisin vektörle çarpımı
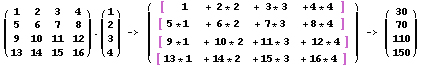
İlk satırı ilk sütunla çarpmak ve bu şekilde devam etmek yerine, ilk sütundaki tüm öğeleri vektörün ilk öğesiyle, ikinci sütundaki öğeleri vektörün ikinci öğesiyle çarparak devam edeceğiz. Bu şekilde, sonuç yeni 4X4 matrisi olacak. Bundan sonra, bir satırdaki dört öğenin tümünü toplayarak bulduğumuz sonuç olan 4X1 matrisine ulaşırsınız.
MPI API, bu sorunu çözmek için doğrudan uygulayabileceğiniz bazı işlevlere sahiptir; bunlar Liste 1'de gösterilmiştir.
Liste 1. MPI kullanılarak yapılan Matris çarpımı
|
Kümeler performans sağlamak üzere oluşturulurlar ve ne kadar hızlı olduklarını bilmeniz gerekir. Genellikle performansı, işlemci hızının etkilediği düşünülür. Bu bir bakıma doğru olsa da, farklı sağlayıcıların işlemcileri ya da aynı sağlayıcının farklı işlemci grupları karşılaştırıldığında önemsiz hale gelir çünkü farklı işlemciler belirli sayıda saat döngüsünde farklı miktarda iş yaparlar. Bu durum özellikle 1. Bölüm'de vektör işlemcileriyle sayısal işlemciler arasında yaptığımız karşılaşmada belirgindi.
Performansı ölçmenin daha doğal bir yolu da bazı standart testleri yürütmektir. Zaman içinde, LINPACK testi olarak bilinen test, performans karşılaştırması için altın değerinde bir standart haline geldi. Bu test Jack Dongarra tarafından on yıldan fazla zaman önce yazıldı ve hala top500.org tarafından kullanılıyor (bağlantı için Kaynaklar başlıklı konuya bakın).
Bu test N doğrusal denklemlerinden oluşan yoğun bir sistemin çözülmesini içerir; bu denklemlerde kayan noktalı işlem sayısı bilinir (N^3 sırasına ait). Bu test bilimsel uygulamaları ve simülasyonları çalıştırmaya yönelik test bilgisayarlarının hızlandırılması için çok uygundur çünkü bu tür işlemler bir aşamada doğrusal denklemleri çözebilirler.
Standart ölçü birimi, saniyedeki kayan noktalı işlem sayısıdır (FLOPS) (bu örnekte, kayan noktalı işlem (flop), 64 bitlik bir sayıyı toplama ya da çarpma işlemidir). Test aşağıdakileri ölçer:
- Rpeak, teorik olarak en fazla flops. Haziran 2005 tarihli bir rapora göre, IBM Blue Gene/L'nin hızı, 183.5 tflops (trilyon flops) değerindeydi.
- Nmax, en yüksek flops değerini veren N matris büyüklüğü. Blue Gene için bu değer 1277951'dir.
- Rmax, Nmax için elde edilen flops sayısı. Blue Gene için bu değer 136.8 tflops idi.
Bu sayıları değerlendirebilmek için şunu düşünün: IBM BlueGene/L'nin bir saniyede yapabildiklerini ev bilgisayarınızın yapması beş gün sürebilir.
Şimdi kendi Linux kümenizin performansını nasıl karşılaştırabileceğinize bakalım. LINPACK dışında kullanabileceğiniz diğer testler HPC Challenge Benchmark ve NAS karşılaştımalı değerlendirmeleridir.
Linux kümenizin karşılaştırmalı değerlendirmesi
Linux kümenizde LINPACK testini çalıştırmak için LINPACK paralel sürümüne sahip olmanız ve bunu küme için yapılandırmanız gerekir. Bu süreci adım adım göreceğiz.
Uyarı: Aşağıdaki örnekte genel doğrusal cebir kitaplıkları kullanılmıştır; bu örneği yalnızca kılavuz olarak kulanın. Gerçek bir test için kendi ortamınız için optimize edilmiş kitaplıklar edinin.
LINPACK testinin paralel (MPI) sürümü olan hpl.tgz dosyasını netlib.org adresinden yükleyin (bağlantı için Kaynaklar bölümüne bakın).
Önceden derlenen BLAS (Basic Linear Algebra Subprograms) sürümü olan blas_linux.tgz dosyasını yine netlib.org adresinden yükleyin. Kolaylık olması açısından, önceden derlenen BLAS for Linux başvuru uygulamasını kullanabilirsiniz, ancak daha iyi sonuçlar almak için donanım sağlayıcınızdan edindiğiniz BLAS sürümünü kullanmanız ya da bunu açık kaynak ATLAS projesini kullanarak otomatik olarak ayarlamanız gerekir.
mkdir /home/linpack; cd /home/linpack
(herşeyi /home dizinine yükleyeceğiz).
Sıkıştırılmış blas_linux.tgz dosyasını çıkarın ve açın. blas_linux.a adlı bir arşiv dosyası olmalıdır. Bu dosyayı görürseniz, verilebilecek hataları göz ardı edin.
Sıkıştırılmış hpl.tgz dosyasını çıkarın ve açın. hpl adlı bir dizin oluşturulur.
Make.Linux_PII_FBLAS dosyası gibi yapılandırma dosyalarını hpl/setup dizininden hpl dizinine kopyalayın ve hpl dizinindeki kopyanın adını Make.LinuxGeneric olarak değiştirin.
Make.LinuxGeneric dosyasını değerleri kendi ortamınıza göre değiştirerek aşağıdaki gibi düzenleyin:
TOPdir = /home/linpack/hpl
MPdir = /tmp/mpich-1.2.6
LAlib = /home/linpack/blas_linux.a
CC = /tmp/mpich-1.2.6/bin/mpicc
LINKER = /tmp/mpich-1.2.6/bin/mpif77
Bu beş konum, 1. adımda LINPACK'in en üst dizinini, MPICH kurulumunuzun en üst dizinini ve 2. adımdaki başvuru BLAS arşivinin yerini belirtir.
Şimdi HPL'yi derleyin:
make arch=LinuxGeneric
Hata verilmezse, /home/linpack/hpl/bin/LinuxGeneric dizininde xhpl ve HPL.dat adlı iki dosya oluşacaktır.
LINPACK testini kümenizde çalıştırmadan önce, /home/linpack dizininin tamamını kümenizdeki tüm makinelere kopyalayın. (Kümenizi OSCAR'ı kullanarak yarattıysanız ve NFS payları yapılandırıldıysa, bu adımı atlayın.)
Şimdi, cd komutuyla 8. adımda yarattığınız yürütülebilir
dosyaların olduğu dizine geçin ve bazı testleri çalıştırın (örneğin /tmp/mpich-1.2.6/bin/mpicc -np 4 xhpl). Bazı
testlerin çalıştırıldığını ve sonuçların GFLOP olarak
sunulduğunu göreceksiniz.
Not: Yukarıdaki adım matris büyüklüklerinin varsayılan ayarlarına göre bazı standart testleri çalıştıracaktır. Testlerinizi ayarlamak için HPL.dat dosyasını kullanın. Ayarlamayla ilgili ayrıntılı bilgi /home/linpack/hpl/TUNING dosyasında yer alır.
Kendi kümenizi oluşturduğunuza göre şimdi küme tabanlı süper bilgisayarlarda en son teknoloji olan Blue Gene/L'ye hızlı bir şekilde göz atabiliriz. Blue Gene/L çok büyük oranların hesaplanması için gerçekleştirilen bir mühendislik atılımıdır ve bu teknolojinin hakkını verecek bir tartışma bu makalenin amacı dışındadır. Bu nedenle yalnızca yüzeysel bir bakış sunacağız.
Üç yıl önce bir vektör işlemcisi olan Earth Simulator en hızlı süper bilgisayar olduğunda, birçok kişi, bir süper bilgiişlem platformu olarak kümenin sonunun gelmekte olduğunu ve vektör işlemcinin yeniden dirileceğini öngörmüştü; ancak bu erken bir tahmindi. Blue Gene/L, standard LINPACK testinde Earth Simulator'u açık arayla geride bıraktı.
Blue Gene/L ticari iş istasyonlarından oluşturulmamıştır ancak yine de bu yazı dizisinde anlatılan standart kümeleme kavramlarını kullanır. Kümemizde kullandığımız MPICH'den türetilen bir MPI uygulamasını kullanır. Ayrıca, 700MHz hızında standart 32 bit PowerPC® CPU'ları çalıştırır (her ne kadar bunlar çip üzerinde sistem ya da SoC teknolojisini temel alsa da). Bu da sınıfının diğer tüm makinelerinden çok daha az soğutma ve güç gereksinimi olmasını sağlar.
Büyük bir makine olan Blue Gene/L (her biri özel bir işletim sisteminde çalışan) 65.536 hesaplama düğümüne ve (Linux çekirdeğini çalıştıran) 1.024 özel G/Ç düğümüne sahiptir. Bu kadar fazla sayıda düğümle, ağ işlemleri özel önem kazanır ve Blue Gene/L, her biri belli bir amaç için optimize edilen beş farklı türde ağ kullanır.
IBM Systems Journal'ın yeni sayılarından biri özel olarak Blue Gene/L konusunu ele almaktadır; ayrıntılı bilgi için bu yayına başvurabilirsiniz. Blue Gene/L'de, yüksek oranda ölçeklenebilir bir MPP gerçekleştirilmesini ve küme tabanlı bilgiişlem paradigmasının önemini korumaya devam ettiğinin kesin kanıtını görüyoruz.
Bilgi Edinme
-
İki bölümden oluşan bu yazı dizisinin
"Kümeleme
ilkeleri" adlı ilk bölümünü okuyun (developerWorks, Eylül 2005).
-
Jamaica
Project derleyicileri, paralel duruma getirme işlemlerini,
dinamik derleyicileri ve süper bilgisayarların paralel işlemler
kullanılarak optimize edilmesi konularını açıklar.
- Parallel Virtual Machine (PVM)
- PVM, heterojen yapıdaki bir grup UNIX® ve/veya Windows® bilgisayarının, tek bir büyük paralel işlemci olarak kullanılmak üzere bir ağ tarafından bağlanmasına izin veren bir yazılım paketidir.
- PVM'nin MPI'ye göre avantajları adlı PostScript yazısını yükleyebilirsiniz.
- Bu makalede mükemmel bir PVM ve MPI karşılaştırmasını bulabilirsiniz.
- Message Passing Interface (MPI)
- MPI Forum, MPI standardını tanımlayan ve sürdüren birçok kuruluşun temsilcisinin yer aldığı açık bir gruptur.
- MPICH, MPI'nın taşınabilir ve ücretsiz sunulan bir uygulamasıdır.
- LAM/MPI, MPI belirtiminin araştırma ve üretim amaçlı olarak geliştirilen yüksek kalitede bir açık kaynak uygulamasıdır.
- Çalışmalarınıza bu MPI kuruluş kılavuzu ile başlayabilirsiniz.
-
OSCAR (Open Source
Cluster Application Resources), HPC kümelerinin oluşturulması,
programlanması ve kullanılmasına ilişkin en önemli yöntemlerin anlık
görünümüdür.
-
Rocks Cluster açık
kaynak bir Linux küme uygulamasıdır.
-
OpenPBS Portable
Batch System'ın özgün sürümüdür.
-
Clumon, National Center
for Supercomputing Applications'ta Linux süper kümelerini takip etmek
için geliştirilen bir küme izleme sistemidir.
- Karşılaştırmalı değerlendirmeler
- Top500.org sitesinde LINPACK testiyle ilgili genel bilgiler sunulmaktadır.
- Jack Dongarra'nın HPC Challenge testi ve bununla ilgili genel bilgileri konu alan mükemmel bir yazısı.
- NAS Parallel Benchmarks (NPB) paralel süper bilgisayarların performansını değerlendirmek üzere tasarlanan küçük bir program grubudur.
- HPL, dağınık bellekli bilgisayarlarda yüksek performanslı LINPACK testinin taşınabilir bir uygulamasıdır.
- BLAS (Basic Linear Algebra Subprograms) temel vektör ve matris işlemlerini gerçekleştirmek için standart yapı taşları sağlayan yöntemlerdir.
- ATLAS (Automatically Tuned Linear Algebra Software) projesi, deneysel teknikler uygulanarak taşınabilir performans sağlamak üzere yürütülmekte olan bir araştırma çalışmasıdır. Şu anda, taşınabilir özellikte verimli bir BLAS uygulaması için C ve Fortran77 arabirimleri sağlar.
-
IBM Journal of Research and Development yayının bu basımı
BlueGene/L konusunu ele alır.
- Kendi kümenizi oluşturun:
- Building a Linux HPC Cluster with xCAT (Redbook, Eylül 2002) sistem mimarlarına ve mühendislerine, küme teknolojisi hakkında temel bir yaklaşım edinme ve Linux Yüksek Performanslı Bilgiişlem (HPC) kümesinin kurulması konularında yol gösterir.
- Linux HPC Cluster Installation (Redbook, Haziran 2001) Kuruluş ve yönetim için xCAT (xCluster Administration Tools) araçlarını konu alır.
- Building an HPC Cluster with Linux, pSeries, Myrinet, and Various Open Source Software (Redpaper, Temmuz 2004) bir pSeries düğümleri topluluğunun ve bir Myrinet ara bağlantısının, gerçek bir HPC üretim işyükünün bir Linux kümelenmiş ortamında çalışabilmesine olanak verecek bir şekilde nasıl bir araya getirildiğini anlatmaktadır.
- Build a heterogeneous cluster with coLinux and openMosix (developerWorks, Şubat 2005) karışık ya da melez bir HPC Linux kümesinin nasıl oluşturulduğunu göstermektedir.
- Linux Clustering with CSM and GPFS (Redbook, Ocak 2004) Linux kümeleri için Küme Sistemi Yönetimi ve Genel Paralel Dosya Sistemi konularını ele alır.
-
developerWorks
Linux zone sayfasında Linux geliştiricilerine yönelik
kaynaklar yer alır.
Ürün ve teknoloji edinme
- Karşılaştırmalı
sınamaları yükleyin
- En güncel LINPACK sonuçlarını yükleyin.
- Kişisel bilgisayarınızda kendi Java tabanlı LINPACK testinizi çalıştırın.
- HPL testini edinin.
- BLAS alt rutinlerini edinin.
- ATLAS'ı yükleyin.
-
Ücretsiz
SEK for Linux ürününü sipariş edin; bu ürün DB2®,
Lotus®, Rational®, Tivoli® ve WebSphere® üzerinde
Linux için en güncel IBM deneme yazılımlarını içeren ikili DVD
setidir.
-
Bir sonraki geliştirme projenizi Linux üzerinde oluşturmak için
IBM
deneme yazılımını doğrudan developerWorks sayfasından yükleyin.
Tartışma
-
developerWorks
blogs'a katılarak developerWorks topluluğuna
erişebilirsiniz.
Aditya Narayan, Kanpur'daki Indian Institute of Technology'de Fizik alanında lisans ve lisansüstü eğitim almıştır ve QCD Microsystems'i kurmuştur. Windows ve Linux'un iç işleyişi, WebSphere ve J2EE ve .NET gibi kurumsal platformlar konusunda uzmandır. Aditya çoğunlukla New York'ta yaşamaktadır. Aditya Narayan'a aditya_pda@hotmail.com adresinden erişebilirsiniz.






